Advancing PyTorch Performance on Arm: Key Enhancements in the 2.9 Release
As part of the new PyTorch 2.9 release, Arm contributed key enhancements to ensure seamless performance and stability on Arm platforms. Learn more about the enhancements in this blog post.
By Ashok Bhat

This blog post is published on behalf of Aditya Tewari, Nikhil Gupta and Arm’s PyTorch Engineering Team
As part of the new PyTorch 2.9 release, Arm contributed key enhancements to improve performance and stability on Arm platforms. This includes updated library support via oneDNN and OpenBLAS optimizations and AArch64 reliability fixes. These advances align with the release’s broader focus on expanding hardware compatibility and strengthening deployment reliability across the ecosystem.
Accelerating PyTorch on Arm
The PyTorch 2.9 release brings performance and reliability improvements across the Arm CPU backend
We focused on four areas of improvement:
- Extended operator coverage and enhanced performance for convolution, activation, and quantized operators on AArch64.
- Performance uplift using Scalable Vector Extensions (SVE/SVE2).
- Strengthened TorchInductor and vectorization correctness for Arm backends.
- Expanded Arm continuous integration (CI) coverage and improved testing infrastructure.
Together, these updates ensure that models running on Arm CPUs benefit from optimized math libraries, improved kernel performance, and consistent compiler behavior.
Extending operator coverage and performance
A key focus for this release was expanding and optimizing the set of PyTorch operators available on AArch64. These included:
- Convolution and Activation Improvements: Core kernels were tuned for better cache utilization and vectorized math execution, improving convolutional neural network (CNN), and image-based workloads.
- Quantized Operator Expansion: Enhanced quantized operator implementations improve inference speed.
- Runtime Consistency and Correctness: Updates across the operator stack ensure consistent numerical results between eager and compiled execution paths.
Boosting math performance with SVE and SVE2
Arm’s SVE and SVE2 enable flexible vector lengths, allowing code to scale efficiently across different CPUs. PyTorch 2.9 introduces optimizations that better leverage this hardware capability:
- Enhanced vectorized math routines in oneDNN and OpenBLAS.
- Optimized GEMM and reduction kernels.
- Better vector alignment and correctness handling in TorchInductor.
This improves throughput and efficiency across transformer, CNN, and mixed-precision workloads.
Compiler and runtime enhancements for Arm
PyTorch 2.9 includes multiple compiler and runtime updates:
- AOTInductor Vectorization: Improved automatic vectorization and graph lowering for Arm architectures.
- Optimized Runtime Configurations: Runtime backend cpp_wrapper was tuned for better scheduling and reduced CPU overhead.
- Mixed-Precision Handling: Improved fusion and precision handling in compiler passes ensure consistent results and faster execution.
These updates make PyTorch’s compiler stack more robust for Arm targets, providing more general optimizations. Transformer-based models such as BERT and Llama, which spend over 40% of their runtime in GEMM operations (e.g. torch.Linear) see up to 2.5× speedup.
Ecosystem integration and continuous testing
Long-term reliability and maintainability are ensured through stronger integration and validation in PyTorch’s continuous integration (CI) and testing infrastructure.
- Expanded CI Coverage: CI now includes Neoverse V2 based AWS Graviton 4 instances.
- Smarter Tensor Handling: Better test coverage for edge cases ensures correctness across various tensor shapes and datatypes.
- Upgraded Math Libraries: OpenBLAS 0.3.30 introduces architecture-aware optimizations for matrix operations, boosting linear algebra performance. As a result, TorchBench, HuggingFace, and TIMM test suites in torch.compile mode are faster than Eager mode.
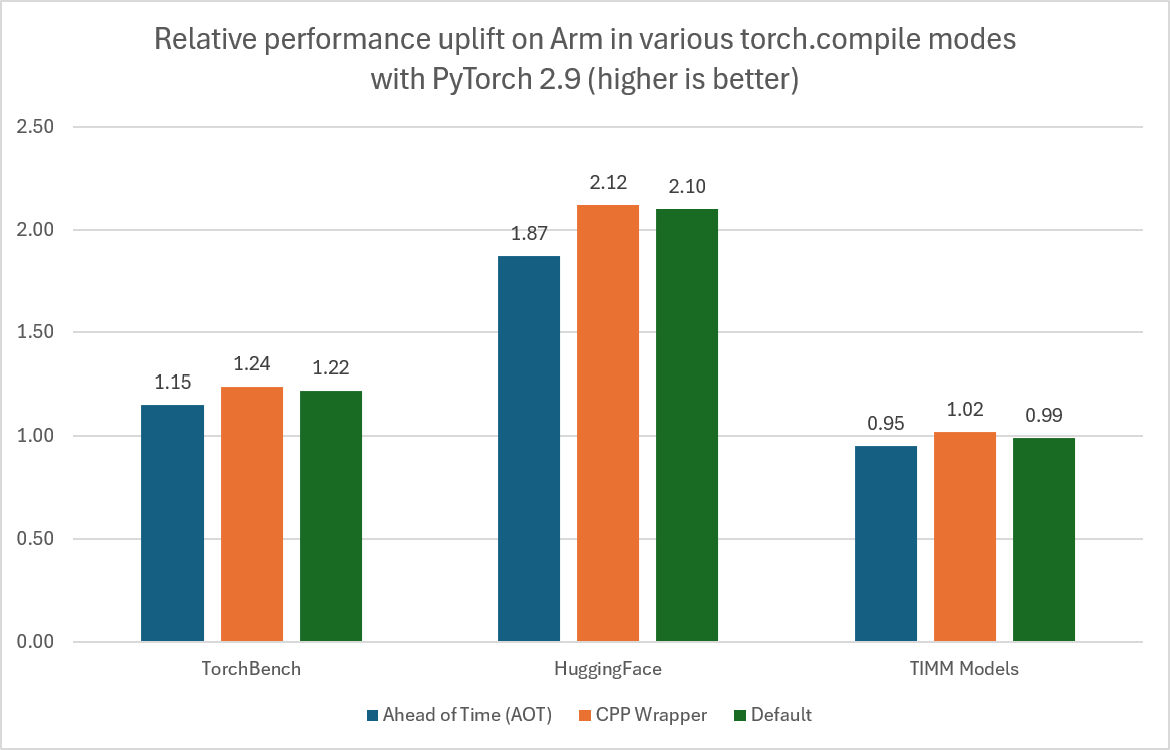
Detailed results are available on the PyTorch HUD Dashboard.
Looking ahead
With PyTorch 2.9, Arm and the PyTorch community continue to demonstrate how to deliver high-performance AI on Arm CPUs.
Future work will focus on:
- Expanding operator-level optimizations with deeper SVE/SVE2 integration.
- Enhancing TorchInductor’s scheduling and code generation on the Arm architecture.
- Further strengthening Arm-native CI coverage to maintain upstream reliability.
As the PyTorch ecosystem continues to evolve, Arm remains committed to enabling open, efficient, and scalable AI performance across the global developer community.

By Ashok Bhat
Re-use is only permitted for informational and non-commercial or personal use only.
