Bringing SGLang high-performance LLM inference to Arm Neoverse
SGLang, the popular high-throughput LLM serving engine, now runs on Arm Neoverse CPUs with W8A8 quantization added for dense and MoE models, and a dedicated Arm64 CI pipeline established for production-ready LLM inference.
By Yibo Cai

SGLang is widely used as a high-throughput LLM serving engine. The project has more than 27,000 GitHub stars.
SGLang introduces RadixAttention for efficient prefix-aware KV-cache reuse. It also supports rich features like continuous batching, prefill and decode disaggregation, and speculative decoding. For large deployments, SGLang uses a distributed, hierarchical KV-cache architecture. HiCache tiers cache across GPU HBM, host DRAM, and distributed storage such as Mooncake. Mooncake disaggregates the KV-cache into a shared cluster-wide pool over RDMA fabrics for cross-node KV-cache reuse.
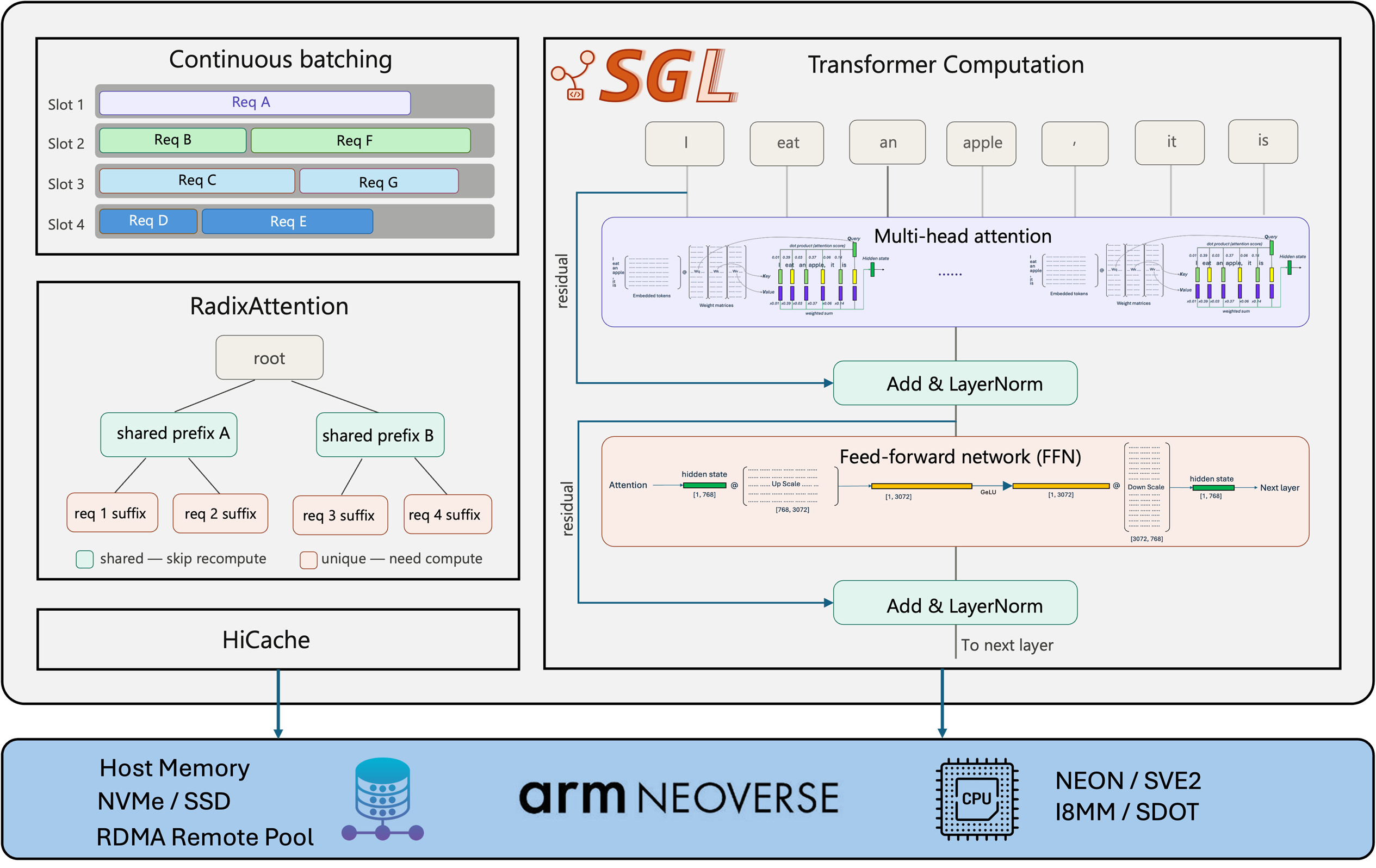
SGLang was originally developed with GPU execution and x86 CPU paths as first-class targets. Arm Neoverse CPUs are among the most powerful processors available today. They deliver exceptional performance-per-watt and performance-per-dollar. Arm Neoverse-based servers include wide SIMD pipelines such as SVE2 andNEON, high-bandwidth memory system, and low memory-access latency. These features suit the memory-bound, bandwidth-constrained workloads that dominate LLM inference. Arm also performs well in storage and networking workloads which support KV-cache spilling and disaggregation.
This blog describes our contributions to enable SGLang inference to Arm Neoverse. These include:
- Refactoring the codebase to remove x86-specific assumptions
- Adding INT8 quantization and Mixture-of-Experts (MoE) model support
- Integrating official Arm CI
These changes make LLM serving production-ready on Arm.
Enable SGLang on Arm64 CPU
The sgl-kernel CPU execution path was built around Intel-specific assumptions. GEMM kernels assumed x86 VNNI and BRGEMM routines that are not available on Arm. Intel AMX-specific weight pre-packing changed expected data layouts. x86 intrinsics throughout the codebase failed to compile on Arm.
PR #12527 and #14867 refactored SGLang CPU codebase to remove assumptions that tied CPU execution to x86 platforms.. This work established BF16 inference on PyTorch with the oneDNN and ACL backend as a stable baseline for Arm systems.
Production deployments increasingly use quantized models to improve throughput and reduce memory use. The W8A8 format, which uses8-bit weights and 8-bit activations, has become a practical standard for CPU inference. Compared to BF16, W8A8 halves memory bandwidth requirements and enables integer SIMD acceleration on modern hardware.
PR #16045 adds W8A8 INT8 support for Arm platforms. This support covers both dense transformer models and sparse MoE architectures which is an increasingly important capability as MoE models become more common.
The refactored codebase organizes kernels into architecture-specific source directories and selects the correct subtree at build time. This approach enables INT8 GEMM kernels optimized for Arm’s I8MM (smmla) and dot-product (sdot) instructions to coexist in the same repository as Intel AMX kernels, without a tangle of #ifdef guards.
Accuracy evaluations showed that W8A8 quantized models produced negligible degradation compared to full-precision baselines.
Set up dedicated Arm64 CI
Enabling SGLang on Arm requires a robust continuous integration (CI) pipeline that prevents regressions.
PR #22123, merged in May 2026, establishes a PR-gated test lane for Arm. It includes two key components:
- Native Arm64 Dockerfile: This provides a reproducible build environment for Arm64 systems, separate from the existing x86 container image. It ensures that Arm builds are self-contained and that library dependencies resolve to Arm-native packages.
- Dedicated GitHub Actions workflow. This workflow runs for every pull request that modifies CPU-related paths. It runs on GitHub-hosted Arm64 runners and covers the full integration workflow: container builds, SGLang installation, sgl-kernel compilation, and a curated test suite.
What is next?
As AI systems evolve from isolated inference toward agentic workflows coordinating multiple models, tools, and memory layers, efficient orchestration becomes increasingly important.
- Integrate KleidiAI into SGLang to improve CPU inference performance on Arm.
- Add new features such as CPU MoE offloading and additional quantization formats such as INT4.
- Expand CI coverage with additional test cases as native Arm implementations continue to arrive.
Summary
SGLang now runs on Arm Neoverse CPUs. We removed x86-specific assumptions, added W8A8 INT8 quantization for dense and MoE models, and established a dedicated Arm64 CI pipeline. Next, we plan to improve performance, add features, and expand CI coverage.

By Yibo Cai
Re-use is only permitted for informational and non-commercial or personal use only.
