Optimize Llama.cpp with Arm I8MM instruction
Boosted Llama.cpp Q6\_K & Q4\_K inference using Arm's I8MM (smmla) for faster, efficient int8 matrix multiplies on Neoverse-N2 CPUs.
By Yibo Cai

Optimize Llama.cpp with Arm I8MM instruction
This blog post introduces our practice in optimizing Llama.cpp Q6_K and Q4_K quantized model inference with Arm I8MM featured instructions. More specifically, the signed 8-bit integer matrix multiply accumulate instruction smmla.
Understanding Llama.cpp quantization
Llama.cpp is an open-source C++ library for running large language models, optimized for fast CPU inference. It leverages techniques like quantization (for example, 8-bit or 4-bit integer formats) to reduce memory usage and accelerate computations, enabling efficient model deployment on consumer and server-grade hardware.
Llama.cpp supports different kinds of quantization. Quantization balances model accuracy and performance. Smaller data sizes improve inference speed but can reduce accuracy by increasing perplexity.
For example, Q8_0 uses 8-bit integer to represent one datapoint, while Q6_K reduces data size to 6 bits.
Quantization is done in blocks. Data points in a block share a single scale factor.
For example, Q8_0 is processed in blocks of 32 datapoints, as explained here:
- Retrieve 32 floating-point values from the original data, write down as f[0:32]
- Calculate maximal of absolute values, that is, mf = max(abs(f[0:32]))
- Calculate scale_factor = mf / (max(int8)) = mf / 127
- Quantization: q[i] = round(f[i] / scale_factor)
- Dequantization: v[i] = q[i] * scale_factor
Q6_K is more complicated. As shown in the picture below, datapoints are organized in two levels:
- One super block of 256 datapoints. One super block scale factor in floating point format.
- Each super block consists of 16 blocks. There are 16 datapoints in each block, which share one block level scale factor in integer format.

Figure1: Llama.cpp Q6_K quantization
Optimize Llama.cpp with Arm I8MM instruction
Like most AI workloads, for LLM inference, most CPU cycles are cost in matrix multiplication. Arm I8MM, more specifically, the smmla instruction accelerates 8-bit integer matrix multiplication.
To explain what smmla does and why it’s efficient, assume we want to multiply two matrices in the following figure.
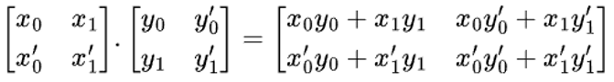
Figure 2: matrix multiplication
Following the textbook approach, we can calculate the four scalars in the output matrix one by one. That is, the first output scalar is the inner product of the first row of matrix x with the first column of matrix y. Four inner product operations are required.
There’s a more efficient way to do it with outer product. As shown in the following figure, we can instead multiply the first column of matrix x with the first row of matrix y to get the four partial output scalars in one shot. Sum the two partial outputs lead to the result. Only two outer product operations are necessary.
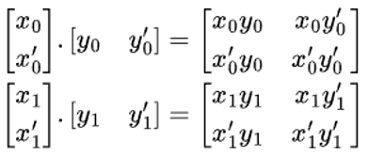
Figure 3: outer product
smmla implements vector level outer product, as the picture below shows. Please note vmmlaq_s32 is the compiler intrinsic implements smmla instruction.
- Each input vector (int8x16) is divided into two int8x8 vectors
- Calculate inner product of the four int8x8 vector pairs
- Store results to the four lanes in the output vector (int32x4)
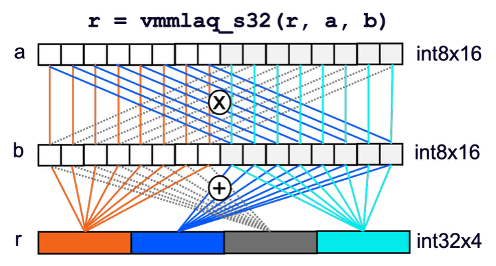
Figure 4: smmla instruction
Armed with smmla instruction, we can accelerate matrix multiplication by progressing in two rows and two columns. As explained in the following figure, the computation steps are:
- Load two rows (int8x16) from matrix x to vx0 and vx1, two columns from y to vy0 and vy1.
- Zip vx0, vx1 to combine bottom halves of the two vectors to one vector, and upper halves to another one. This is necessary for smmla to work correctly. Same for vy0, vy1.
- Calculate four temporary scalar results with two smmla instructions.
- Progress to next blocks and accumulate temporary results until all data is consumed
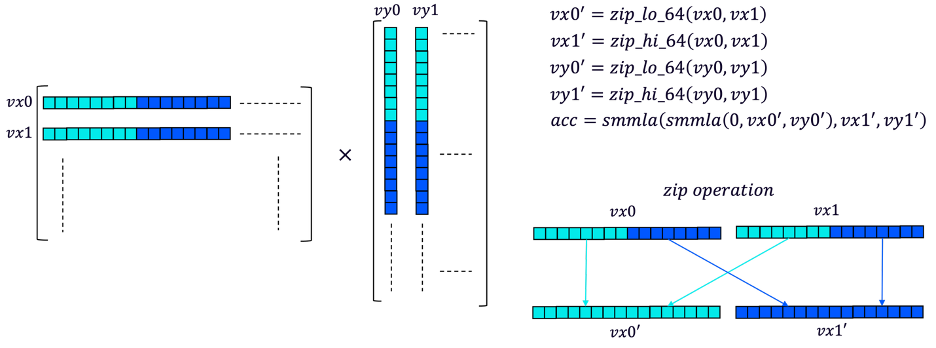
Figure 5: matrix multiplication with smmla
We optimized Llama.cpp Q6_K and Q4_K matrix multiplication kernels with smmla and observed big performance uplift. Picture below compares Llama.cpp performance before and after Q6_K optimization:
- S_TG: speed of token generation, higher the better
- S_PP: speed of prompt prefills, higher the better
The test platform is Arm Neoverse-N2.
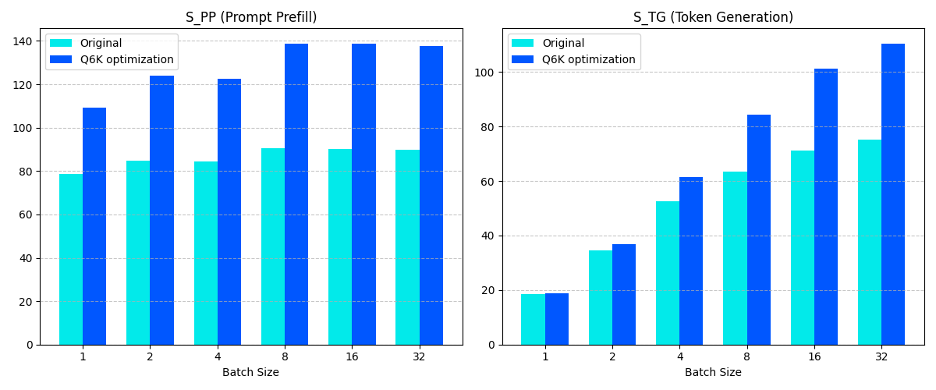
Figure 6: Arm I8MM improves Llama.cpp Q6_K model performance
Upstream patches for reference:

By Yibo Cai
Re-use is only permitted for informational and non-commercial or personal use only.
