Rethinking robotics reinforcement learning: A practical humanoid training workflow on DGX Spark
Arm enables robotics training at scale with Isaac Sim, supporting full AI workflows from build to deployment on a single DGX Spark system
By Odin Shen

Reinforcement learning (RL) for robotics is often associated with large GPU clusters, distributed infrastructure, and x86-based development environments. Training a humanoid robot with high-fidelity simulation is a resource-intensive workflow that runs in the data center.
What if that workflow could run on a single workstation?
In this blog post, we explore a complete robotics pipeline built with Isaac Sim and Isaac Lab on NVIDIA DGX Spark, powered by the Grace–Blackwell (GB10) Superchip. We compile the software stack natively on Arm. We run large-scale parallel simulations. We train a humanoid robot to walk over rough terrain.
Building a native robotics stack on Arm
The workflow begins by building Isaac Sim and Isaac Lab from source directly on the Grace CPU (aarch64).
The full stack is compiled natively on Arm without cross-compilation or an x86 build host. This includes:
- GCC 11
- CUDA 13
- Git LFS
- Omniverse simulation components
This produces:
- native aarch64 binaries
- full CUDA acceleration
- tight Grace CPU and Blackwell GPU integration
- no architecture translation layers
This is an important result for Arm developers. High-fidelity robotics simulation has traditionally been treated as an x86-centric workflow. In practice, the full Isaac Sim and Isaac Lab toolchain can run natively on Arm.
More importantly, this native workflow reduces the friction of cross-compilation and environment switching. The same Arm-based development model can support multiple stages of robotics AI development. It supports workstation experimentation, larger-scale training, and eventually edge deployment. This Cloud-to-Edge consistency makes Arm compelling for real-world AI systems.
DGX Spark combines:
- Grace CPU for orchestration, compilation, and data preparation.
- Blackwell GPU for simulation and neural network acceleration.
- NVLink-C2C unified memory to reduce CPU–GPU data movement overhead.
Together, these components form a tightly integrated robotics development platform.
From simulation to scalable RL training
After validated Isaac Sim, the next step is reinforcement learning with Isaac Lab.
The task selected for this experiment is: Isaac-Velocity-Rough-H1-v0.
This environment trains the Unitree H1 humanoid robot, with 19 actuated joints, to:
- follow commanded forward velocity
- maintain balance
- walk across procedurally generated rough terrain
The training pipeline uses RSL-RL, a lightweight reinforcement learning library designed for robotics locomotion workloads, with PPO (Proximal Policy Optimization) as the training algorithm. Training is launched in headless mode to maximize GPU utilization:
To highlight the platform’s parallelism, training is launched in headless mode with num_envs=512:
export LD_PRELOAD="$LD_PRELOAD:/lib/aarch64-linux-gnu/libgomp.so.1"
./isaaclab.sh -p scripts/reinforcement_learning/rsl_rl/train.py \
--task=Isaac-Velocity-Rough-H1-v0 \
--headless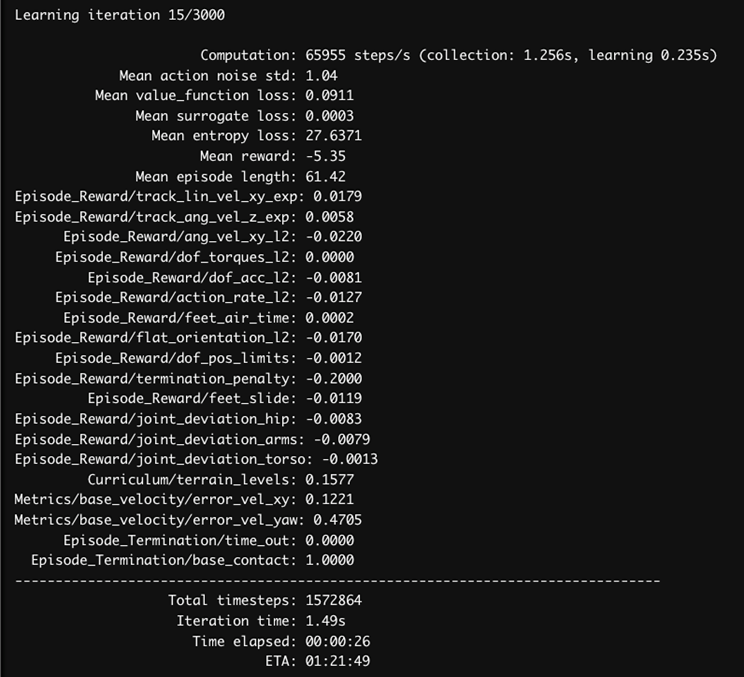
That means the system runs about 65,000 simulation steps per second on a single desktop-class machine.
This level of performance comes from several architectural advantages:
- Physics simulation runs directly on the Blackwell GPU. This enables massive parallelization of joint dynamics across hundreds of environments.
- PPO policy updates operate on batched tensors. This allows reinforcement learning optimization to scale efficiently with parallel simulation.
- The Grace CPU manages orchestration and system control. This keeps simulation and learning pipelines fully utilized without becoming CPU-bound.
A key enabler behind this throughput is the NVLink-C2C interconnect. It provides a high-bandwidth unified memory space between the Grace CPU and Blackwell GPU.
In many reinforcement learning systems, physics simulation runs on the GPU. Training logic runs on the CPU. This forces tensors to move repeatedly across the PCIe bus. This constant data transfer introduces latency and limits overall throughput.
On DGX Spark, NVLink-C2C enables zero-copy data exchange between the CPU and GPU. Physics simulation can run across hundreds of environments on the Blackwell GPU. The PPO algorithm accesses the same memory space for policy updates without traditional host-device transfer overhead.
The result is a tightly integrated training loop. Simulation and learning operate on the same unified memory system. Traditionally, this level of throughput requires a distributed GPU cluster. With DGX Spark, this runs on a single Arm-based workstation.
Watching a humanoid learn to walk
One of the advantages of robotic RL in simulation is that learning progress can be observed directly.
We captured evaluation clips at two checkpoints using num_envs=512.
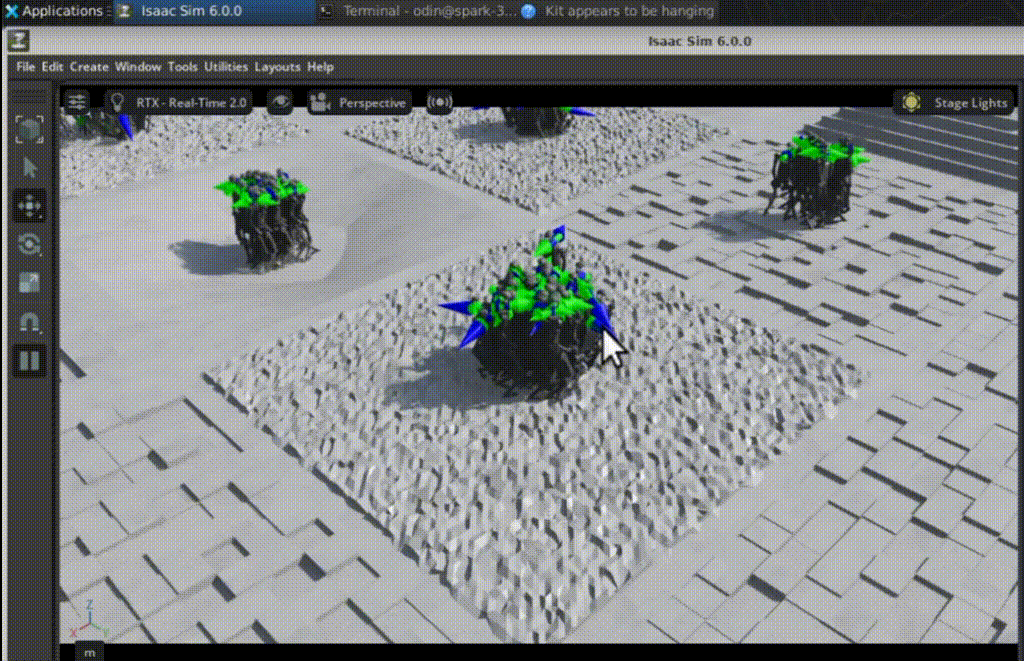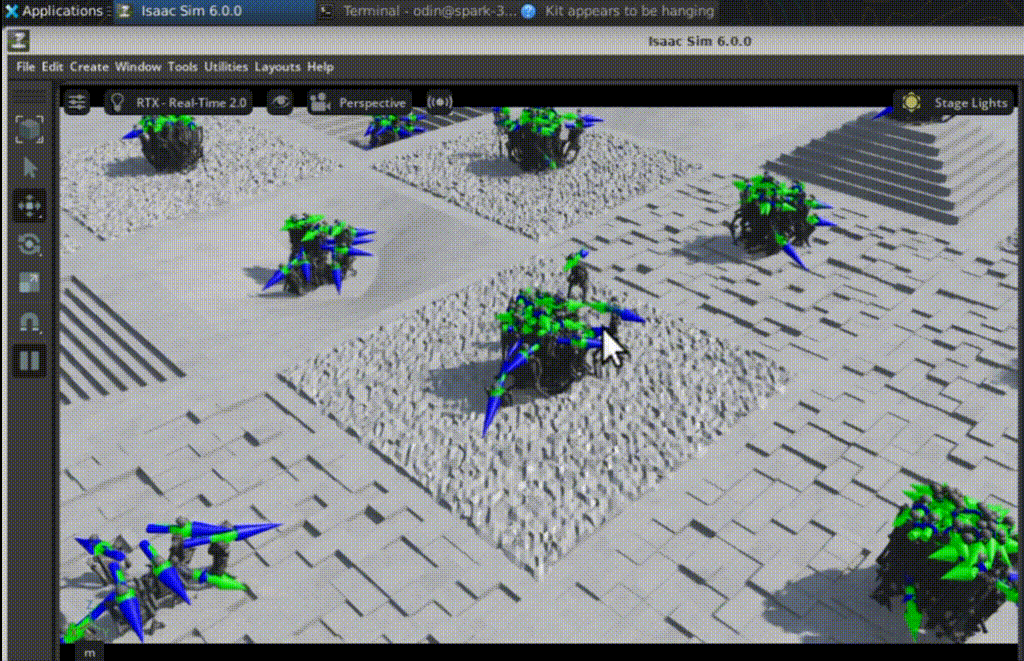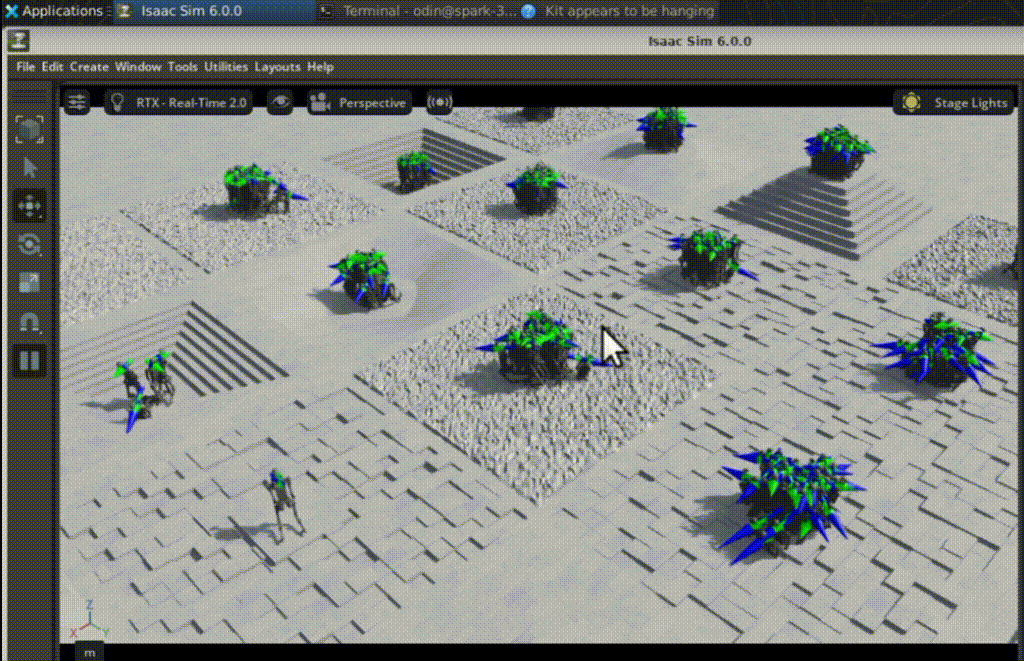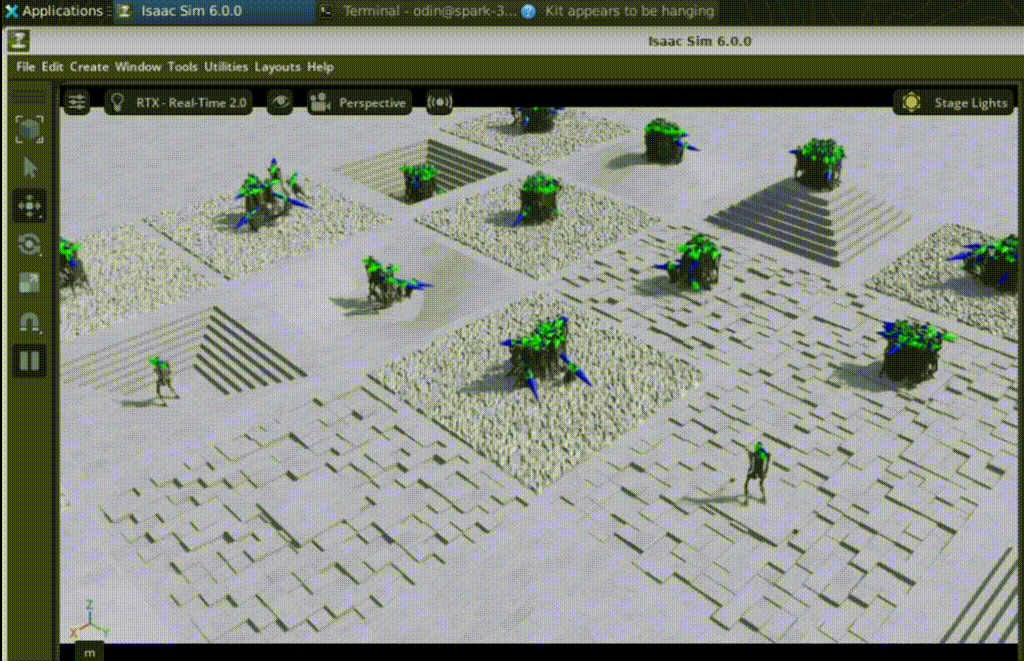
Iteration 50: early exploration
At iteration 50:
- most robots fall almost immediately
- joint actions are noisy and unstable
- no clear gait pattern has emerged
- velocity tracking is ineffective
At this stage, the policy is still exploring. PPO has not yet learned a usable locomotion strategy.
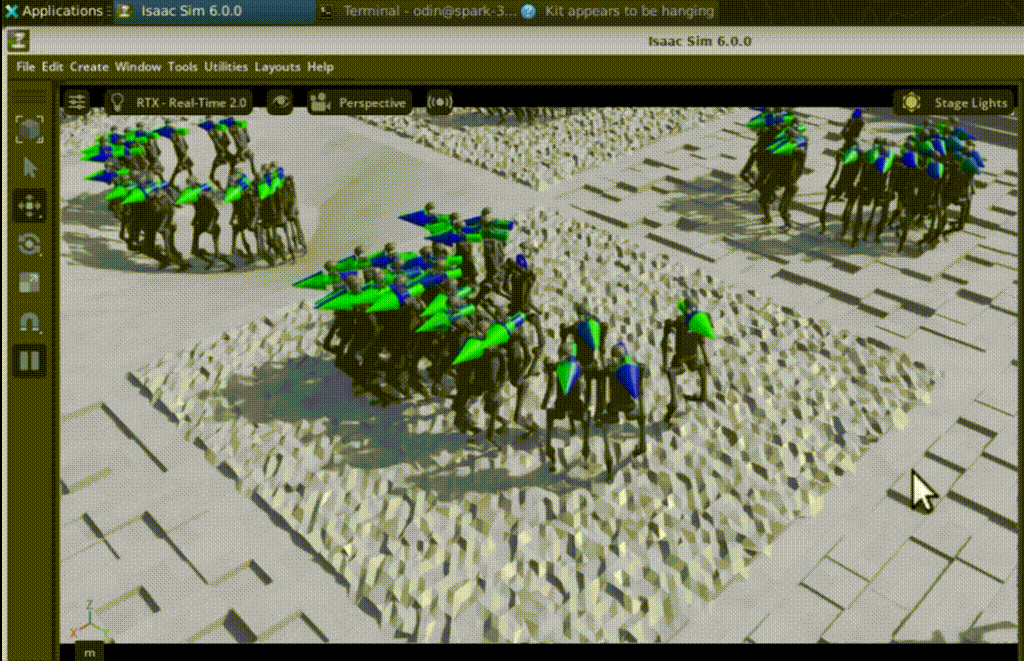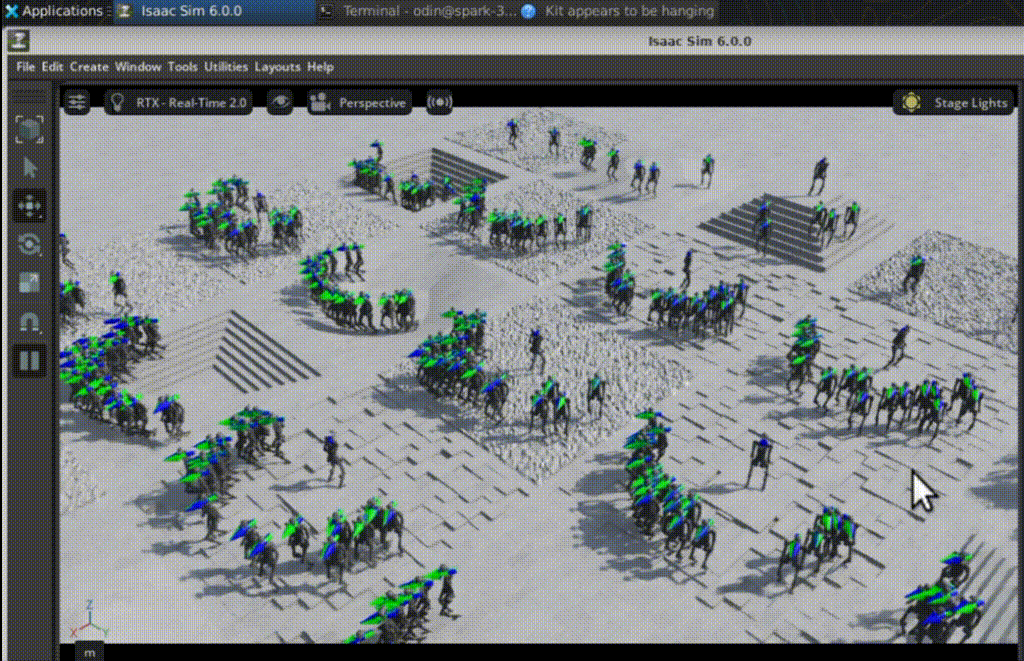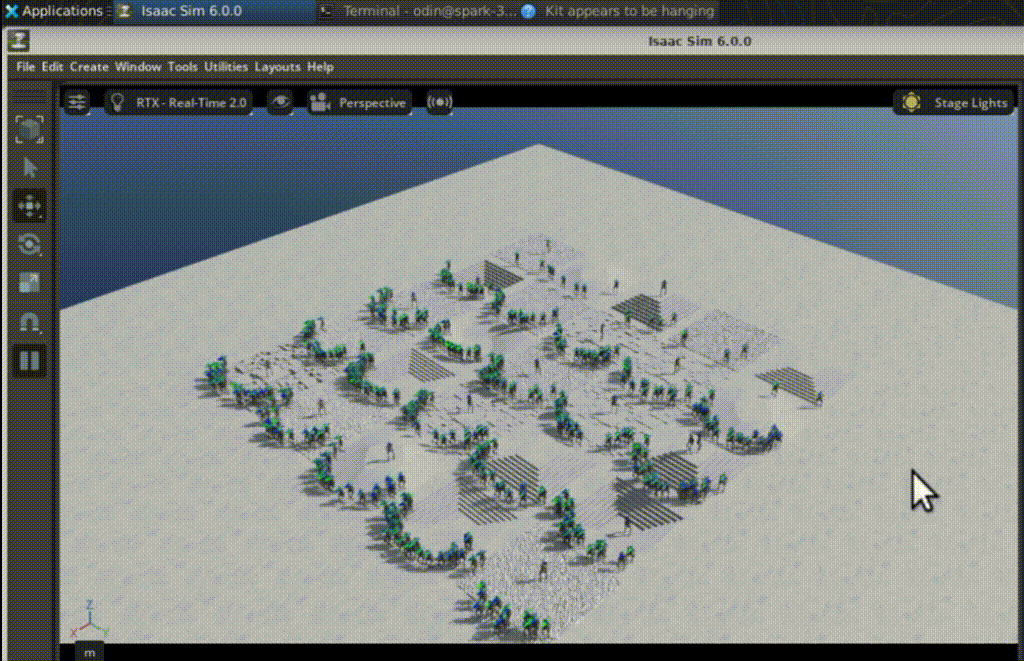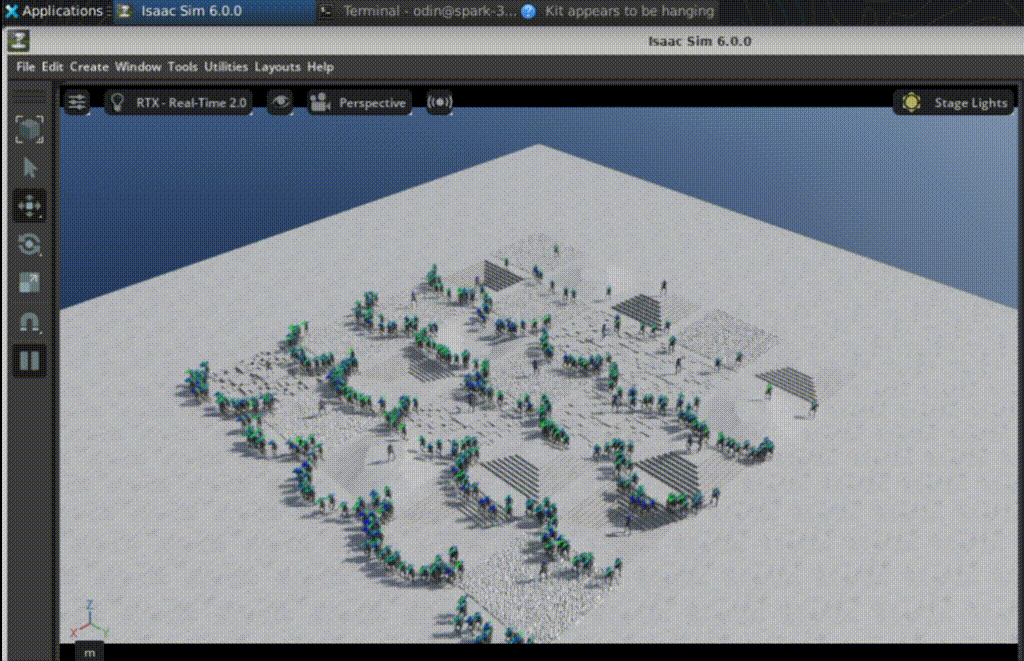
Iteration 1350: stable locomotion
By iteration 1350:
- the humanoid walks forward consistently
- it maintains balance on uneven terrain
- it can recover from small disturbances
- velocity commands are tracked much more accurately
Changes in foot placement, posture control, and gait regularity are clearly visible. Random exploration gradually becomes structured locomotion.
The training metrics reinforce the same story:
- Mean reward increases over time.
- Episode length increases as the robot stays upright longer.
- Value function loss stabilizes.
- Action noise decreases as the policy converges.
- Termination penalties decrease as falling becomes less frequent.
This alignment between visual behavior and log metrics makes the training process interpretable and measurable.
Why this matters for Arm developers
This project is more than a robotics demo. It shows how Arm-native systems support the full lifecycle of a modern physical AI workload.
| Traditional robotics RL | DGX Spark workflow |
| Multi-node GPU clusters | Single Arm-based workstation |
| Separate simulation and training systems | Unified simulation + training stack |
| Heavy CPU–GPU data transfer | NVLink-C2C unified memory |
| x86-centered toolchains | Native Arm robotics workflow |
For Arm developers, the significance is clear:
- Arm supports more than inference workloads.
- Robotics simulation and training can be built natively on Arm.
- Workstation-class systems support serious RL experimentation.
- The same architectural foundation supports development to deployment.
This proves platform-level relevance. It is not about training one humanoid robot. It is about showing that Arm can support a complete robotics workflow, from source build to simulation, training, evaluation, and future deployment.
Final thoughts and continue exploring
In this workflow, we:
- Build Isaac Sim and Isaac Lab natively on Arm.
- Create a high-fidelity robotics simulation environment.
- Train a 19-DOF humanoid robot on rough terrain.
- Achieve about 65,000 simulation steps per second.
- Observe policy convergence from unstable exploration to stable locomotion.
All of this was completed on a single DGX Spark system. As we rethink what is possible for robotics reinforcement learning on a single workstation, the next step is to turn that idea into a reproducible workflow.
To reproduce the workflow described in this blog post, explore the accompanying learning path: Train a Humanoid Locomotion Policy with Isaac Lab on DGX Spark.
This step-by-step guide walks through:
- Building Isaac Sim on Arm.
- Running robot simulations.
- Training a humanoid locomotion policy with Isaac Lab.
Explore the Isaac Lab documentation to try additional environments, tasks, and reinforcement learning workflows.
Train a Humanoid Locomotion Policy with Isaac Lab on DGX Spark learning path

By Odin Shen
Re-use is only permitted for informational and non-commercial or personal use only.
