Rethinking the role of CPUs in AI: A practical RAG implementation on DGX Spark
A detailed look at how CPU-based embedding, unified memory, and local retrieval workflows come together to enable responsive, private RAG pipelines on desktop AI platforms—powered by Arm and DGX Spark.
By Odin Shen

The technical problem: Latency, data fragmentation, and privacy constraints
In many enterprise environments, engineers and technical staff need to find information quickly. They search internal documents such as hardware specifications, project manuals, and technical notes. These materials are often scattered, making traditional search inefficient
These documents are often confidential or proprietary. This constraint prevents these documents from being processed by external cloud services or public large language models (LLMs). The challenge is to implement an AI-powered retrieval system that delivers secure, fast, and contextually accurate answers directly on-device.
The architectural solution: Heterogeneous RAG on DGX Spark
GPUs are often considered the default compute workhorse in modern AI pipelines. The AI inference flow involves multiple distinct stages, each with different compute needs. GPUs are optimized for large-scale matrix operations. Other phases, such as query parsing, data retrieval, and vector encoding, require low-latency and high-flexibility processing.
This is where the DGX Spark desktop platform, built on the Grace-Blackwell GB10 Superchip architecture, provides a foundational advantage:
- Heterogeneous Compute: It combines NVIDIA Blackwell-series GPUs with a high-performance Arm CPU complex (with Cortex-X and Cortex-A cores). The Arm CPU handles the latency-sensitive text embedding stage in the Retrieval-Augmented Generation (RAG) pipeline.
- Unified Memory: The system uses a Unified Memory architecture so the CPU and GPU can share a single memory space.
With this hardware foundation and software stack, including FAISS and llama.cpp, we show how the CPU transitions from a passive pre-processor to an active, latency-optimized engine that drives responsive local AI.
Architecture and design: Running RAG locally on desktop hardware
Retrieval-Augmented Generation (RAG) is an AI architecture well-suited for querying private, on-premises data. This includes internal contracts, unpublished technical documents, and other sensitive materials either absent from public large language models or unsuitable for processing via external cloud services. The strength of RAG lies in its ability to convert such closed-domain knowledge into a searchable vector database. This enables language models to generate responses locally, so you receive AI-assisted answers while preserving data privacy and ownership.
To show how this works in practice, we used a practical and familiar dataset: the full range of Raspberry Pi hardware specifications, programming guides, and application notes. These documents are often long and inconsistently formatted. It is common to spend significant time flipping through PDFs just to find details like GPIO pin assignments, voltage thresholds, or default states.
With a localized RAG system, users can enter natural language questions. The system retrieves relevant passages from a local document database and then generates a contextually accurate answer using a language model. The overall query flow can be summarized in three steps:
- The user inputs a natural language query.
- The system searches the local document database for relevant content.
- The language model generates a natural language response based on the retrieved context.
For our platform, we chose the DGX Spark desktop system from MSI EdgeXpert, built on the Grace-Blackwell GB10 Superchip architecture. It offers thermal and acoustic advantages suitable for edge AI development.
It combines NVIDIA Blackwell-series GPUs with a high-performance Arm CPU complex that includes Cortex-X and Cortex-A cores. It also supports a Unified Memory architecture, so the CPU and GPU share a single memory space. This setup reduces data transfer latency and cuts coordination overhead between compute units.
On this hardware foundation, we implemented the RAG system using the following software stack:
- FAISS for efficient vector search.
- llama.cpp for executing quantized language model inference.
- Python for data processing and orchestrating the overall pipeline logic.
With a quantized language model running on llama.cpp and a prebuilt FAISS vector index, the system can run without any model retraining. Once the documents are loaded and embedded, you can deploy a fully local RAG-based query assistant. This setup offers clear practical value in terms of performance, development flexibility, and data privacy. It also shows that desktop-class AI platforms are feasible for real-world applications.
With the RAG architecture in place, we can now focus on a key decision in system design: where and how to run the embedding stage for best performance and responsiveness.
Why CPUs are a smarter choice in RAG pipelines
In a RAG architecture, the first stage converts a user’s input query into a vector. This is known as text embedding. This step is critical for overall system accuracy, but its computational profile is very different from the large-scale matrix operations GPUs are built for.
In practice, user queries are usually short phrases or single sentences. This makes embedding a low-throughput, latency-sensitive task. Offloading such small batches to the GPU adds unnecessary overhead such as scheduling delays, PCIe transfer latency, and inefficient resource utilization.
This is precisely why we chose to run embedding on the CPU and why the Arm-based SoC in the DGX Spark platform proves to be an ideal match.
DGX Spark includes high-performance Arm Cortex-X and Cortex-A cores in a heterogeneous CPU architecture. The Cortex-X series supports high-frequency, low-latency operation and delivers excellent multithreaded performance with strong energy efficiency. This makes it well-suited for small-batch, memory-intensive inference tasks like embeddings.
Paired with quantized int8 embedding models, these CPUs deliver stable performance under low-power conditions. This ensures fast responses and a smooth interactive experience. For desktop- or edge-class query systems, the Arm Cortex-X architecture is optimized for latency-critical workloads such as real-time search and inference. It balances high single-thread performance with strong power efficiency.
To show why this decision matters, let us look at a real-world example where embedding quality directly affects the reliability of the system’s output.
Grounded answers: Eliminating hallucination with RAG
As mentioned in the section above, the first stage involves text embedding. The quality of the RAG system's output depends on how precise that initial embedding is.
More importantly, RAG is designed to solve the problem of AI hallucination. When language models lack specific context or access to up-to-date documentation, they often generate plausible-sounding responses that are not grounded in facts. This creates serious risks in technical and enterprise domains.
We ran a controlled experiment using a common developer question against internal documentation.
Scenario 1: Language Model (LLM) without RAG
Query: “Which GPIOs on the Raspberry Pi 4 are configured with a default pull-down resistor?”
If the raw query is passed directly to the Meta-Llama-3.1-8B model, without RAG or vector retrieval, the results show how unstable an ungrounded LLM can be:
Trial 1: The model listed GPIOs 1, 3, 5, 7, 9, 11... as having pull-down resistors.
Trial 2 (Same query): The model returned a completely different list (GPIOs 3, 5, 7, 8...) and reclassified pins (for example, GPIO 4, previously listed as pull-up, was classified as pull-down).
Observation: The model remained confident in both trials, despite generating contradictory and factually incorrect results.

This kind of behavior is not unusual. When language models lack specific context or up-to-date documentation, they often produce plausible-sounding responses that are ultimately ungrounded. This issue is known as hallucination and creates serious risks in technical domains.
Scenario 2: The same query with RAG architecture
Query: “Which GPIOs on the Raspberry Pi 4 are configured with a default pull-down resistor?”
When the exact same query was run through our local RAG system, the outcome was completely different:
Factually correct: The response matched the official documentation and verified as correct.
Traceability: The system explicitly referenced the relevant section and table number (e.g., "Table 5: Power consumption...") from the datasheet.
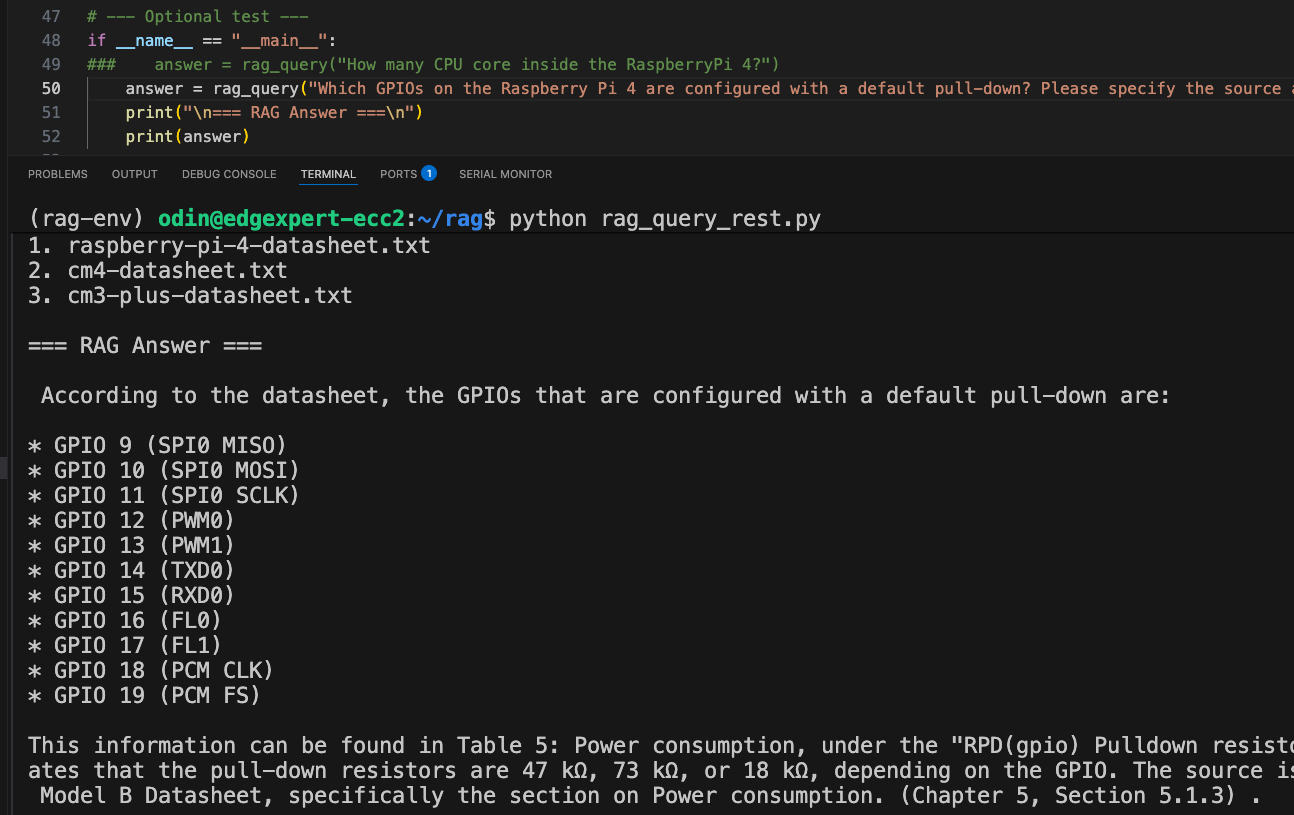
This highlights one of the core strengths of the RAG architecture. Instead of relying on the language model to “guess” based on its training distribution, RAG grounds each response in retrieved, document-based evidence. This approach helps prevent hallucinations and ensures the model answers with real, verifiable information.
From a performance standpoint, the embedding step, handled by the Arm CPU, typically took between 70 to 90 milliseconds. This meets the low-latency requirement for an interactive system.
Architectural Advantage: Unified Memory
In traditional systems, data generated by the CPU must move across an interconnect, such as PCIe, to the GPU's dedicated memory space. This process adds latency and consumes valuable bandwidth. In contrast, the Unified Memory architecture enables the CPU and GPU to share one memory space. This enables the GPU to access output vectors generated by the CPU without doing explicit data copies or transfers. This creates a faster, more efficient pipeline. This is especially beneficial in real-time AI inference scenarios where every millisecond counts.
The following memory profile across RAG stages provides quantitative evidence of this efficiency on the DGX Spark platform.
DRAM usage across RAG execution stages
|
Stage |
Description |
Observed DRAM Usage (Approx.) |
Key Technical Insight |
|
Idle (Pre-launch) |
System idle before RAG tasks are initiated |
~3.5 GiB |
Baseline usage from OS and background services |
|
Model Load |
Launching llama-server, loading LLaMA 3.1 8B Q8_0 model |
~12 GiB |
Model weights mapped directly to Unified Memory for shared access. |
|
Embedding Phase |
Text chunks embedded on CPU using E5-base-v2 model |
~13 GiB |
CPU stores vector data directly into the shared DRAM. |
|
Query Execution |
FAISS retrieval followed by GPU-based generation via llama.cpp |
~14 GiB |
Shared tensors accessed directly by the GPU, eliminating PCIe copy overhead. |
|
Post-completion |
Query completes, partial memory cache released |
~12 GiB |
Model remains in DRAM, ready for next query |
The memory profile across these stages provides valuable insight into how well the system manages resources in a unified memory environment.
Please note:
All performance and memory usage observations reflect our test environment and workload configuration on DGX Spark. Actual results may vary depending on system settings and model size. This profile can serve as a practical reference for planning local AI workloads with predictable memory scaling.
These observations lead to several key insights:
- Stable memory usage across pipeline stages: DRAM use increased from 3.5 GiB at idle to about 14 GiB during peak RAG activity, an overall rise of only ~10 GiB. This shows highly efficient memory control and resource use.
- Models and vector data persist in memory: After the model loads and memory rises to 12 GiB, memory usage remains stable even after multiple queries. This confirms the model and embeddings are not evicted from DRAM, allowing reuse without reloads.
- Minimal memory shifts during CPU-to-GPU transition: Memory usage increased slightly, from 13 GiB during embedding to 14 GiB during GPU generation. This shows that vectors and prompt tensors are directly used by the GPU in-place. No significant reallocations or PCIe transfers occurred.
These metrics reinforce the value of Unified Memory in AI system design. Unified Memory simplifies pipeline integration and enables predictable, low-latency inference behavior on desktop and edge platforms.
These findings validate the architectural importance of Unified Memory in AI system design. Beyond simplifying development, it enables stable and efficient memory behavior throughout execution. It is an important foundation for AI inference on desktop and edge-class platforms.
Developers can find the complete example and step-by-step instructions from this blog post in the Arm Learning Path. Whether you are building a proof-of-concept or planning a production deployment, these modular tutorials offer a fast and reliable way to work with real RAG workflows. They use CPU-efficient embedding and Unified Memory on Arm-based platforms.
Conclusion: The CPU is a critical collaborator in AI system design
Building and running a local RAG system on DGX Spark has reshaped our understanding of the CPU’s role modern AI architectures.
In many real-world AI applications, especially those centered around retrieval, search, and natural language interaction, much of the computational workload occurs outside the core language model inference. Tasks like query handling, text embedding, document retrieval, and prompt assembly are the domains where CPUs excel.
The implementation on DGX Spark validates two important architectural components:
- Latency-optimized processing: The high-performance Arm CPU complex (Cortex-X/A cores) is proven to be the superior choice for handling the low-throughput, latency-sensitive embedding stage. This approach removes unnecessary overhead associated with scheduling small batches on the GPU and ensures fast response times.
- Seamless compute collaboration: The Unified Memory architecture enables the data generated by the CPU to be accessed by the GPU without manual data transfers or synchronization. This collaboration removes a performance bottleneck and enables each processing unit to focus on its optimized task.
The result is that the CPU is not a passive pre-processor but an active, latency-optimized engine that is important for inference responsiveness on desktop platforms.
As AI continues to move toward on-device and edge deployments, the role of the CPU, particularly the high-efficiency Arm architecture, will become more central. This project shows that DGX Spark is more than a hardware showcase. It is a fully capable development platform for real-world prototyping.
Now is the time for developers to reconsider the CPU’s position as a core enabler in the future of low-latency, privacy-preserving AI systems.

By Odin Shen
Re-use is only permitted for informational and non-commercial or personal use only.
