The agentic inflection point and how Arm AGI CPU powers the next phase of AI infrastructure
Why the rise of enterprise AI agents demands a new class of infrastructure and why the Arm-native stack, anchored by the Arm AGI CPU, is the architecture built for this moment

Enterprise AI is entering a new phase, one defined not by single model inference. Autonomous systems now coordinate multiple models, tools, and data sources in real time. These agentic workloads fundamentally change how infrastructure is stressed. Infrastructure now requires more concurrency, more orchestration, and more CPU-bound operations.
This shift has major implications for infrastructure. Agentic systems drive significantly more concurrency, more coordination, and more compute than traditional inference workloads. A growing share of this work runs on the CPU. This is why the Arm AGI CPU has emerged as a new foundation for AI data centers. It runs models and strengthens the orchestration layer that increasingly determines performance, efficiency, and scale.
| $57B | 42% | 4x | 90.6% | 2x |
| Agentic AI market by 2031 Mordor Intelligence, 2026 | CAGR 2026–2031 Mordor Intelligence, 2026 | CPU demand growth, Agentic AI Arm CEO Rene Haas, Mar 2026 | Agentic latency from CPU ops Georgia Tech Research | Arm AGI CPU perf/rack vs. x86 Arm Holdings, Mar 2026 |
The Arm AGI CPU is built on the Arm Neoverse platform and designed specifically for this new class of workloads. It combines high core density, bandwidth, and deterministic performance in a production-ready design. It is the next step in extending Arm’s role in AI infrastructure, from proven cloud deployment to purpose-built silicon for the agentic era.
|
Arm AGI CPU — Technical Specifications |
|
|
Process |
TSMC 3nm N3P |
|
CPU Cores |
136 Arm Neoverse V3 |
|
Clock Speed |
3.5 GHz all-core / 3.7 GHz boost |
|
TDP |
300W |
|
Memory Bandwidth |
800 GB/s aggregate |
|
Memory Capacity |
6 TB DDR5-8800 (12 channels) |
|
Memory Latency |
Sub-100 nanoseconds |
|
PCIe |
96 lanes Gen6 |
|
Memory Expansion |
CXL 3.0 native |
|
Air-Cooled Rack |
8,160 cores (36kW) |
|
Liquid-Cooled Rack |
45,696 cores (200kW) |
|
Capex Savings |
~$10B vs x86 at 1GW scale |
|
OEM Systems |
Supermicro, Lenovo, ASRockRack |
The full stack: Arm AGI CPU as the Agentic head node
In agentic systems, inference is no longer a single model call. It is a continuous pipeline of model execution, coordination, and data movement.
This shifts two critical responsibilities to the CPU:
- Orchestration: scheduling agents, routing tasks, managing memory and I/O
- Execution support: handling tool calls, pre/post-processing, and system-level logic
CPUs now do more than support inference. They are central to scaling it.
The Arm AGI CPU is purpose-built for this role. It delivers the throughput, memory bandwidth, and deterministic performance required to sustain large-scale, multi-agent inference workloads.
The Arm AGI CPU acts as the orchestration layer. It coordinates inference workloads while offloading model execution to purpose-built accelerators. This separation enables each layer to scale independently and maintain overall system efficiency. Arm works closely with partners across the ecosystem to co-design these systems. This approach ensures that inference performance, power efficiency, and system balance are optimized end-to-end.
Agentic AI cluster: reference architecture
|
Applications |
Enterprise AI Agents · Multi-Agent Orchestration · RAG Pipelines |
|
Serving |
vLLM · Triton · Kubernetes / OpenShift |
|
Head node CPU |
Arm AGI CPU (136× Neoverse V3 · 300W · 800 GB/s · CXL 3.0) |
|
Accelerators |
Rebellions Rebel100 NPU (144GB HBM3E · 4.8 TB/s) | Positron Atlas/Asimov (2TB RAM · 5× tokens/watt) | Furiosa Renegade (180W TDP) |
|
Fabric |
800 GbE Scale-Out Network (RebelPOD / Positron Cluster / Renegade Rack) |
|
Storage |
Distributed Object Storage · Vector DB · CXL Memory Expansion |
This composable architecture separates orchestration compute, handled by the Arm AGI CPU, from inference compute, Custom AI accelerators. Each layer can scale, upgrade, and optimize independently. This is a fundamental advantage over monolithic, vertically-integrated systems that combine these functions into a single proprietary stack.
The Arm AGI CPU works with with purpose-built inference accelerators from companies such as Rebellions, Positron, and Furiosa. Together, they provide a coherent, production-ready answer to this shift that enterprises can deploy today.
Rebellions: Purpose-built inference at rack scale
Rebellions, founded in 2020 and is backed by Arm, Samsung, SK hynix, SK Telecom, and Aramco. The company is becoming a major provider of AI inference infrastructure, with a stack that spans silicon to rack-scale deployment.
The flagship Rebel100 was unveiled at ISSCC 2026. It is a quad-chiplet NPU that combines four chiplets, 144 GB of HBM3E, 4.8 TB/s of memory bandwidth, and 512 MB of on-chip SRAM. It also includes QoS features that reduce long-tail latency in multi-tenant inference environments.
At the system level, Rebellions scales this architecture through RebelRack and RebelPOD. Its latest collaboration with Arm and SK Telecom extends the story beyond hardware into sovereign AI and telecom infrastructure.
Announced on April 10, 2026, the partnership combines Rebellions’ RebelCard, based on Rebel100, with Arm AGI CPU in a co-optimized server platform. SK Telecom will validate the platform in their AI data center for sovereign AI models and telecom-scale workloads. This deployment reinforces the case for Arm AGI CPU as the control plane for efficient, large-scale agentic AI infrastructure [17].
|
Rebellions Rebel100 NPU — Specifications |
|
|
Architecture |
Quad-chiplet UCIe-Advanced |
|
Process |
Samsung SF4X (3nm-class) |
|
HBM3E Memory |
144 GB per chip |
|
On-Chip SRAM |
512 MB per chip |
|
Memory Bandwidth |
4.8 TB/s per chip |
|
RebelRack |
32 NPUs / rack |
|
FP8 Performance |
16 PFLOPS per rack |
|
FP16 Performance |
8 PFLOPS per rack |
|
Agg. HBM3E |
4.5 TB per rack |
|
Scale-Out System |
RebelPOD (up to 1,024 NPUs) |
|
Power Efficiency |
35–70% less than GPU (MDPI, 2025) |
|
Total Funding |
$850M (pre-IPO, 2026) |
Positron AI: Memory-first inference at a fraction of the power
Positron AI was founded in 2023. The company uses a memory-first approach to inference that focuses on latency, power efficiency, and deployability instead of training-class peak compute. Their Atlas shipping platform was built specifically for LLM inference. It uses air-cooled without liquid cooling, and the company says it has delivered materially lower latency and much lower power consumption than competitive systems in production inference workloads.
Positron extended this strategy into their next-generation roadmap with Asimov and the Titan appliance. According to Positron, Asimov is a purpose-built inference chip with more than 2 TB of memory per accelerator. Titan combines four Asimov chips into an 8 TB+ system and scales to more than 100 TB at rack level, targeting trillion-parameter models and very long context windows without liquid cooling.
In February 2026, Positron also raised an oversubscribed $230 million Series B at a valuation above $1 billion. Arm participated as a strategic investor. This investment strengthens Positron’s role as a memory-centric, power-efficient complement to Arm-based agentic AI infrastructure [14].
|
Positron Atlas + Asimov — Specifications |
|
|
Shipping Product |
Atlas (available now) |
|
Atlas Latency |
3x lower vs. a competitive system |
|
Atlas Power |
⅓ of a competitive system's draw |
|
Atlas Cooling |
Air-cooled (no liquid required) |
|
Next-Gen |
Asimov (Coming in 2027) |
|
Asimov RAM/Accel. |
2 TB per accelerator |
|
Asimov RAM/System |
8 TB per Titan system |
|
Rack-Scale RAM |
100+ TB total |
|
Asimov Efficiency |
5x tokens per watt vs. competitive GPUs |
|
Origin |
USA-designed and built |
|
Series B |
$230M (Feb. 2026, Arm as investor) |
FuriosaAI: Efficient LLM inference moves into mass production
FuriosaAI was founded in 2017. The company is building inference-first AI infrastructure around its second-generation accelerator, RNGD, also called Renegade. The chip targets LLM and multimodal inference workloads. It is built on the TSMC 5nm process and uses a 180W power profile. The chip also provides 1.5 TB/s of HBM3 bandwidth and PCIe Gen5 x16 connectivity, and the ability to partition a single chip into multiple isolated NPUs for multi-tenant deployments.
Furiosa is now moving from product launch to commercial scale. According to TheElec, the company began mass production of Renegade this year. Furiosa plans to ship it to Samsung SDS for cloud deployment starting in July and is targeting 20,000 units of production in 2026.
At the system level, Furiosa packages Renegade into the NXT RNGD Server. This rack-scale, air-cooled platform targets enterprise, cloud, and agentic AI workloads. Furiosa says the server integrates eight Renegade cards and delivers up to 20 PFLOPS per rack. The system operates within an approximately 3 kW rack power envelope.
This design highlights the company’s emphasis on practical, power-efficient inference infrastructure instead of GPU-style brute force scaling. This positioning aligns with the broader Arm strategy for efficient AI data center compute. Furiosa is an example of the accelerator ecosystem emerging around Arm-powered AI infrastructure [18].
|
FuriosaAI Renegade — Specifications |
|
|
Shipping Product |
Renegade (RNGD, now in mass production) |
|
Process |
TSMC 5nm |
|
Performance |
512 TOPS INT8 / 1024 TOPS INT4 |
|
Memory |
48 GB HBM3 |
|
Memory Bandwidth |
1.5 TB/s |
|
Host Interface |
PCIe Gen5 x16 |
|
Multi-Tenancy |
Partitionable into 2, 4, or 8 isolated NPUs |
|
Power |
180W |
|
Cooling |
Air-cooled deployment profile |
|
Next Revision |
HBM3E version planned |
|
Next-Gen Memory |
72 GB HBM3E per accelerator |
|
Total Funding |
$247M |
Why enterprises should move now
The value of the Arm, Rebellions, Positron, and Furiosa stack extends beyond specifications. The combination of Arm AGI CPU with these accelerators delivers best-in-class total cost of ownership (TCO). It also provides customers with greater sovereignty while meeting required LLM inferencing performance targets.
Total cost of ownership
At gigawatt AI factory scale, the AGI CPU allows customers to claim 2x performance-per-watt savings compared to x86 systems. These gains come from higher rack density, lower TDP per useful core, and a simpler thermal design that avoids the cost of custom liquid cooling infrastructure. [5]
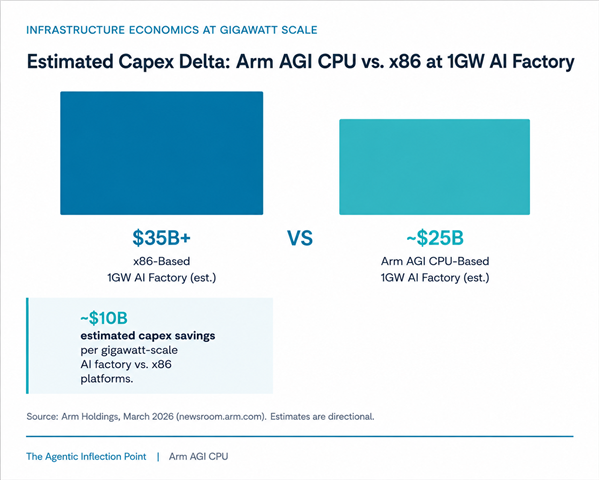
Open ecosystem & supply resilience
Arm is contributing the Arm AGI CPU reference design to the Open Compute Project (OCP) under the DC-MHS standard. This approach supports a broad ecosystem and vendor neutrality. Rebellions builds its stack on open standards, including vLLM, PyTorch, Triton, HuggingFace, and OpenShift. Positron delivers an OpenAI API-compliant endpoint. [6,10,13]
The architecture of the agentic decade
The transition to agentic AI is not a feature upgrade. It is a structural shift in software design, AI deployment, and hardware requirements for cost-efficient scaling. These workloads require higher concurrency, coordination, and token throughput. They also place new and increasing demands on the CPU.
In this environment, the Arm AGI CPU delivers a step change in efficiency and scalability. It can deliver up to 2x performance per rack compared to x86 systems. The platform also provides a broad and open software ecosystem and significant capital expenditure advantages at data center scale.
The Arm AGI CPU also works with a rapidly expanding accelerator ecosystem that includes Rebellions, Cerebras, Positron, and Furiosa. Together, these technologies provide a composable and production-ready foundation for agentic AI infrastructure.
The Arm AGI CPU will empower some of the world’s largest technology companies including Meta, OpenAI and Cloudflare. Organizations that adopt this architectural shift right now will carry that advantage for years.
Infrastructure decisions made at the start of the agentic era will shape performance, cost, and flexibility over the long term and are not easily reversed. An Arm-native, open, and composable stack is well positioned to meet what comes next.
Learn more about how agentic AI is reshaping infrastructure from cloud to edge in our Newsroom blog post:
What is agentic AI and why its reshaping AI from cloud to edge
Sources & References
[1] Mordor Intelligence, "Agentic AI Market Report 2026-2031," 2026
[2] Gartner, "40% of enterprise apps to include AI agents by 2026," 2025
[3] UiPath, "2025 Agentic AI Report," survey of 252 U.S. IT executives
[4] Georgia Tech Research, CPU latency profiling of 5 agentic workloads (cited in TechSpot, March 2026)
[5] Arm Holdings newsroom, "Arm AGI CPU Launch," newsroom.arm.com, March 24, 2026
[6] Arm Holdings, arm.com/products/cloud-datacenter/arm-agi-cpu, March 2026
[7] HPCwire/AIwire, "Arm Flexes with New Data Center CPU for AI Inference," April 2026
[8] Tom's Hardware, "Arm launches its first data center CPU," March 2026
[9] Futurum Group, Arm cloud data center market share analysis; Data Center Knowledge, March 2026
[10] Rebellions, "Rebellions Closes $400M Pre-IPO," rebellions.ai; Next Platform, April 2026
[11] Tom's Hardware, "ISSCC 2026: Rebellions details Rebel100," March 2026
[12] MDPI Systems, "Performance and Efficiency Gains of NPU-Based Servers over GPUs," Sept. 2025
[13] Positron AI, positron.ai/about; Positron press releases, 2024-2026
[14] Positron AI, "$230M Series B Announcement," The AI Insider, February 2026
[15] Deloitte, "State of AI in the Enterprise 2026," deloitte.com, January 2026
[16] Landbase, "39 Agentic AI Statistics Every GTM Leader Should Know in 2026"
[17] Businesswire, " Rebellions Collaborates with SK Telecom and Arm Targeting Sovereign AI and Telecom Infrastructure"
[18] TheElec, " FuriosaAI to Mass Produce Second-Gen AI Chip, Supply to Samsung SDS Cloud from July"

Re-use is only permitted for informational and non-commercial or personal use only.
