Arm and NauWork partner to scale agentic AI hiring for the semiconductor industry
Explore how NauWork uses AI agents, Snowflake, and Arm-based compute to deliver scalable, cost-efficient talent matching for semiconductor teams

Semiconductor companies operate at the edge of innovation. Roadmaps move quickly. Architectures evolve rapidly. Competition for highly specialized engineering talent is intense. For many organizations, hiring speed has become a critical dependency for product execution.
NauWork is increasing leveraging Arm-based compute to build an AI-native recruiting platform purpose-built to address this challenge. Unlike traditional recruiting systems retrofitted with AI features, NauWork was designed from the ground up as an agentic AI platform. It combines structured data engineering, large-scale inference, and cost-efficient cloud infrastructure to deliver precision talent matching at scale.
For the Arm developer community, this collaboration illustrates how novel AI-native platforms can be created from a systems design standpoint. NauWork treats hiring as a large-scale inference and orchestration problem that depends heavily on efficient compute and data architecture.
Hiring as a large-scale inference problem
Modern semiconductor hiring goes beyond keyword search. Matching a SoC architect, PHY design engineer, or kernel optimization expert to the right team requires semantic understanding of technical depth, toolchains, domain experience, and architecture specialization.
At scale, this becomes a systems problem:
- Millions of candidate-job pair evaluations.
- Embedding generation and similarity scoring.
- Multi-model ensemble ranking.
- Iterative inference and shortlist refinement.
- Automated engagement workflows.
Each open role triggers high-volume computation across large candidate datasets. Precision and recall must balance against compute cost. Latency affects recruiter workflows. Infrastructure design directly affects platform economics.
NauWork addresses this challenge by building an AI-native architecture with clear separation between its data layer, inference systems, and agentic workflows.
Architectural overview
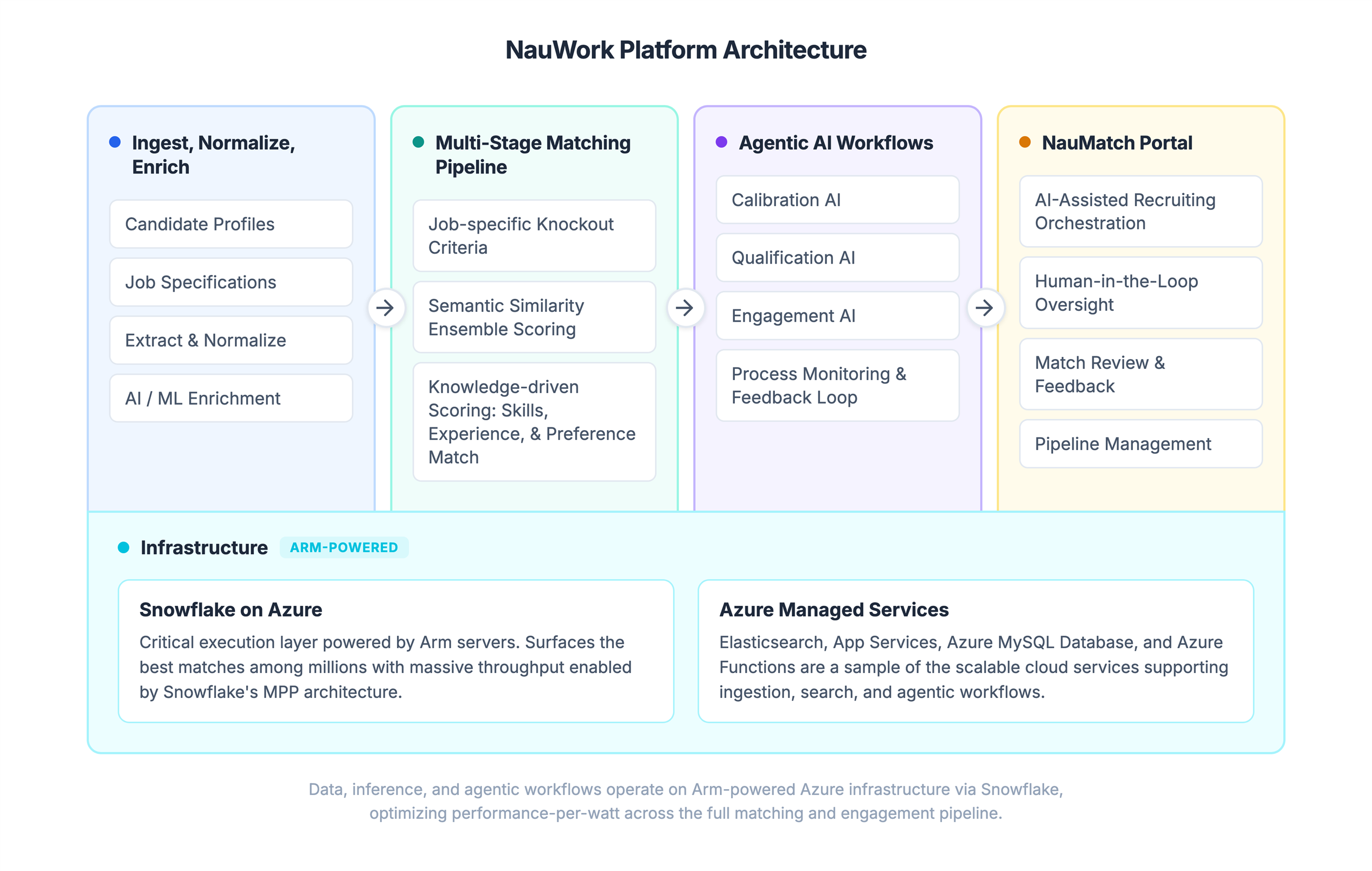
Nauwork’s platform ingests candidate and job data, extracts and leverages signals for matching, and shortlists the most qualified candidates for engagement with maximum efficiency. The architecture diagram above highlights four main functional areas and their supporting infrastructure.
Ingest, normalize, enrich: Profiles are ingested from candidate onboarding and third-party vendors. LLM workflows and machine learning models extract skills, infer missing attributes, and map candidate data to Nauwork’s custom taxonomies. This normalization creates clean, structured data for candidates and jobs. It unlocks high quality matching and context engineering for LLMs.
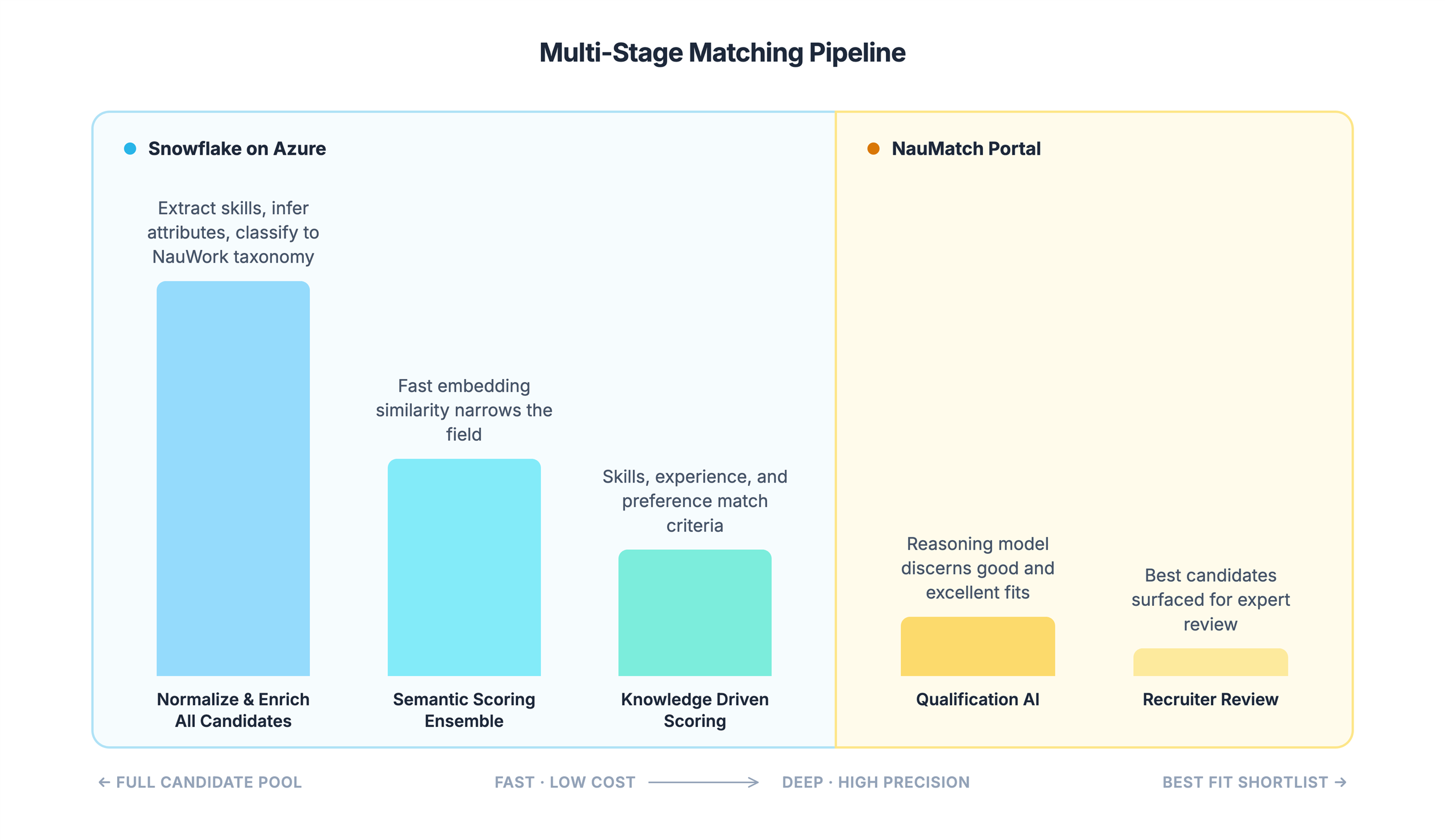
Multi-stage matching pipeline: As data volumes grow, it is critical to narrow the candidate pool before running progressively complex models to determine fit. You do not need a frontier reasoning model to tell you a salesperson is not a fit for an engineering role.
Nauwork uses a multi-stage pipeline. It moves from simple filters to embedding-driven semantic search, then to rules-based algorithms that identify best fit candidates. Only these candidates close to a good fit are submitted for evaluation by the Qualification AI agent and expert recruiters.
Agentic AI workflows: AI agents are embedded throughout the Nauwork platform as chat-based interfaces and background processes. They continuously monitor and respond to activity. These agents help recruiters manage the entire talent acquisition process and provide a frictionless experience for both candidates and hiring managers. AI agents ensure the job is defined correctly and evaluate candidates against the requirements. They present the role to the target audience as quickly as possible.
NauMatch portal: The user-facing application allows recruiters and AI agents to collaborate and execute the process. Recruiters monitor agent activity and guide future actions through feedback at multiple levels. The agent transfers candidates to recruiters when they reach key milestones.
Agentic AI as a platform primitive
NauWork has not added AI to legacy recruitment workflows. It has built the entire hiring lifecycle on task-specific agents that operate with increasing autonomy as confidence grows.
The agent layer is organized around four core functions:
- Calibration AI works with the hiring manager and recruiter to translate role requirements into a structured sourcing plan. It defines knockout criteria, weights skill domains, and sets the parameters that drive downstream matching. This step is critical as match quality depends on specification quality. Most recruiting failures trace back to misalignment at this stage.
- Qualification AI evaluates the shortlist produced by the matching pipeline. It uses reasoning-model inference to assess technical depth, career trajectory, and inferred fit. Rather than scoring candidates on a single axis, it produces structured assessments that explain why a candidate was rated and where uncertainty remains. Recruiters get the context they need to make faster, higher-confidence decisions.
- Engagement AI manages outreach and candidate interaction workflows. After a recruiter approves a shortlist, engagement agents handle initial contact and follow-up sequences. They route candidates back to the recruiters for screening. The system tracks response patterns and recommends changes based on results for similar roles and candidate profiles.
- A continuous feedback loop underpins the system. Recruiter decisions, such as which candidates they advance, reject, or request more like, flow back into the system as training signals. Match weights are recalibrated, sourcing plans are refined, and agent behavior adapts. The system learns from every hiring cycle and compounds its precision over time.
The human recruiter remains central to the process. Their role shifts from manual search, source, and screen to a role of strategic oversight. Agents handle volume. Recruiters apply judgment.
The role of Snowflake and Arm-based infrastructure
The matching pipeline described above runs entirely inside Snowflake. From enrichment to semantic scoring, to knowledge-driven candidate ranking. This is a deliberate architectural choice, and it is important to explain why.
It is common for AI and ML workloads to follow an extract-compute-load pattern. Pull data out of the warehouse, run models in an external compute environment, and write results back. This creates data movement overhead, pipeline complexity, and a management burden that grows with every new model or scoring step. NauWork avoids this completely by pushing compute to where the data already lives.
The Snowflake Snowpark framework allows NauWork to write matching logic as Python stored procedures and user-defined functions. These run natively inside the Snowflake compute layer.
Enrichment models extract skills and classify candidates against NauWork's taxonomy. Embedding similarity scores narrow the candidate pool. Weighted scoring algorithms rank candidates on skills, experience, and preferences. All of these processes run as parallel Python inside Snowflake, and the data never leaves the platform.
The parallelization model is what makes this scale. Snowflake MPP architecture distributes work across elastic compute clusters automatically. Whether a matching run evaluates one hundred candidates or one million, the same stored procedures and UDFs execute. Snowflake handles the distribution. NauWork's engineering team writes matching logic once and lets the platform parallelize it. This avoids the need to build and maintain their own distributed compute infrastructure.
On-demand compute matters just as much. Hiring workloads are bursty. A new requisition for a client can trigger matching across the entire candidate pool, then go quiet for days. Snowflake creates dedicated compute clusters per workload and scales them down when the job completes. NauWork pays for compute only when matching is actively running. This directly impacts platform economics as the customer base grows.
The result is minimal infrastructure management. There are no Spark clusters to tune, no Kubernetes jobs to manage, and no data pipelines moving intermediate results between systems. The matching pipeline runs in Snowflake. The data is in Snowflake. Compute scales on demand inside Snowflake. The engineering team focuses on matching quality and model improvement rather than infrastructure operations.
Running Snowflake on Azure instances powered by Arm-based processors extends this efficiency to the hardware layer. Arm's architecture delivers strong performance-per-watt. This reduces compute costs for sustained, parallel workloads. That is exactly the profile of the NauWork matching pipeline. Since inference and scoring volume scales linearly with customer growth, infrastructure cost efficiency is not an optimization. It is a product requirement. Arm-based compute makes the unit economics work at scale.
Why this matters to engineering leaders
For developers and engineering managers building semiconductor products, hiring delays directly affect roadmap execution. When AI systems can improve match precision and reduce screening overhead, teams regain time and focus.
From a technical standpoint, this collaboration also illustrates a broader pattern that is relevant to many Arm developers:
- AI-native applications demand tightly integrated data and compute architectures.
- Inference-heavy workloads benefit from scalable, parallelized execution models.
- Infrastructure choices influence product economics and long-term sustainability.
The NauWork platform demonstrates how embedding-driven matching, ensemble scoring, and agentic orchestration can operate efficiently when paired with a modern data platform and Arm-based cloud infrastructure.
Looking ahead
Agentic AI systems are reshaping how complex, high-signal workflows are executed across software development, silicon design, and talent acquisition. As this shift accelerates, architectural discipline becomes the key differentiator. Platforms built on structured data layers, scalable inference pipelines, and cost-efficient compute will define the next generation of enterprise AI systems.
The NauWork approach reflects this mindset. It treats hiring as a systems problem, applies embedding-driven semantic matching and ensemble ranking at scale, and uses infrastructure that supports predictable performance and economic efficiency.
For semiconductor and deep-tech organizations, hiring at the speed of innovation is essential. It directly affects product timelines, competitive positioning, and long-term growth.
If you are:
- Interested in exploring how NauWork’s AI-powered talent recruitment can improve match precision, reduce screening overhead, and accelerate your hiring velocity, schedule a meeting at nauwork.com/contact.
- A developer or startup building AI-driven solutions and are interested in leveraging Arm-based cloud infrastructure for industry-leading price-performance and scalable AI workloads, connect with Arm to explore how Arm compute on Azure can support your architecture.
AI-native platforms demand efficient compute. Efficient compute enables scalable AI. Together, Arm and NauWork demonstrate how aligning architecture and infrastructure can unlock both innovation and execution speed. To learn more about the Arm and NauWork partnership please visit the NauWork Page in the Arm Partner Catalog.

Re-use is only permitted for informational and non-commercial or personal use only.
