Accelerate multi-token search in strings with SVE2 SVMATCH instruction
The SVMATCH instruction in Arm SVE2 accelerates multi-token string matches, boosting performance in tasks like JSON decoding.
By Yibo Cai

SVMATCH is an instruction that is introduced by Arm SVE2. This instruction aims to accelerate a very common task in software engineering: to check existence of multiple tokens in a string.
As an example, consider parsing CSV files. To extract records and fields, we must cut input into rows and columns. Rows can be separated by '\r', '\n', and columns are often separated by ','. These 3 tokens must be handled differently than normal input. A trivial CSV parser processes 1 character in each iteration.
To improve performance, we want to parse by batch with Neon vectorization. As explain in the following steps:
- Load multiple bytes into a vector
- Check existence of special tokens in the vector
- Big win if there's no special token.
- Fallback to the trivial character by character approach if special token exists.
Step 2 is critical for performance. That is, how to efficiently check existence of the 3 special tokens ('\r', '\n', ',') in a vector.
Traditionally, we implement it by comparing the vector with 3 tokens separately, then "or” the 3 results. This approach is tedious. More importantly, it does not scale. Image supporting additional tokens, like escape '\' and quote '"', the time complexity increases linearly.
SVMATCH simplifies this task significantly. We can match multiple tokens in constant time.
For example, svbool_t svmatch_u8(svbool_t pg, svuint8_t op1, svuint8_t op2)
- op1 (haystack): a vector contains the input string.
- op2 (needle): a vector contains the tokens to be matched in input string.
- return: a predicate with each bit represents occurrence of any token in the input string.
The following table illustrates the behavior of SVMATCH. The result bits are set for positions where the op1 character exists in op2.
Note as there are only 3 tokens to be matched, op2 vector is populated with duplicated tokens (the comma).
| op1 (input csv string vector) | a | , | 0 | 1 | 2 | 3 | 4 | 5 | 6 | \r | \n | + | - | * | / | ? |
| op2 (special tokens vector) | \r | \n | , | , | , | , | , | , | , | , | , | , | , | , | , | , |
| result (predicate) | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
On Neoverse-N2, SVMATCH costs 2 cycles. We can match at most 16 tokens in a 16 bytes string with 1 instruction. While the traditional approach requires 16 compare and 15 "or" instructions.
Optimize Sonic JSON decoder
This is a real world case to optimize Sonic JSON decoder with SVMATCH.
Sonic is a fast JSON serializing & deserializing library from Bytedance. We profiled Sonic on Neoverse-N2 and found below hot function.
// original code: 4 NEON compare and 3 "or" operations
sonic_force_inline uint64_t GetNonSpaceBits(const uint8_t *data) {
uint8x16_t v = vld1q_u8(data);
uint8x16_t m1 = vceqq_u8(v, vdupq_n_u8(' '));
uint8x16_t m2 = vceqq_u8(v, vdupq_n_u8('\t'));
uint8x16_t m3 = vceqq_u8(v, vdupq_n_u8('\n'));
uint8x16_t m4 = vceqq_u8(v, vdupq_n_u8('\r'));
uint8x16_t m5 = vorrq_u8(m1, m2);
uint8x16_t m6 = vorrq_u8(m3, m4);
uint8x16_t m7 = vorrq_u8(m5, m6);
uint8x16_t m8 = vmvnq_u8(m7);
return to_bitmask(m8);
}This code loads 16 bytes into a NEON register and compares it with 4 tokens (' ', '\t', '\n', '\r'). It uses 4 vectors, compare (vceqq) and 3 vector "or" (vorrq) instructions. This is the typical case we can improve with SVMATCH.
The SVMATCH optimized code is much more concise.
// optimize with SVMATCH
sonic_force_inline svbool_t GetNonSpaceBits(const uint8_t *data) {
const svuint8x16_t v = svld1_u8(svptrue_b8(), data);
// load four tokens: tab(09), LF(0a), CR(0d), space(20)
svuint8x16_t tokens = svreinterpret_u8_u32(svdup_n_u32(0x090a0d20U));
return svnmatch_u8(svptrue_b8(), v, tokens);
}We see significant performance improvement from SVMATCH. In the table:
- Benchmark: Sonic decoder microbenchmarks
- Original: performance of original code
- SVMATCH: performance of SVMATCH optimized code
- Improvement: performance uplift from SVMATCH
| Benchmark | Original (Gi/s) | SVMATCH (Gi/s) | Improvement |
| gsoc-2018/Decode_SonicDyn | 2.38736 | 2.76677 | 15.89% |
| citm_catalog/Decode_SonicDyn | 1.41729 | 1.76191 | 24.32% |
| otfcc/Decode_SonicDyn | 0.39992 | 0.41342 | 3.38% |
| fgo/Decode_SonicDyn | 0.69160 | 0.71630 | 3.57% |
| twitter/Decode_SonicDyn | 1.33604 | 1.58737 | 18.81% |
| twitterescaped/Decode_SonicDyn | 1.24759 | 1.30216 | 4.37% |
| github_events/Decode_SonicDyn | 1.38961 | 1.65635 | 19.20% |
| canada/Decode_SonicDyn | 0.52615 | 0.52452 | -0.31% |
| poet/Decode_SonicDyn | 2.06297 | 2.40383 | 16.52% |
| lottie/Decode_SonicDyn | 0.41990 | 0.43882 | 4.51% |
| book/Decode_SonicDyn | 0.45662 | 0.48720 | 6.70% |
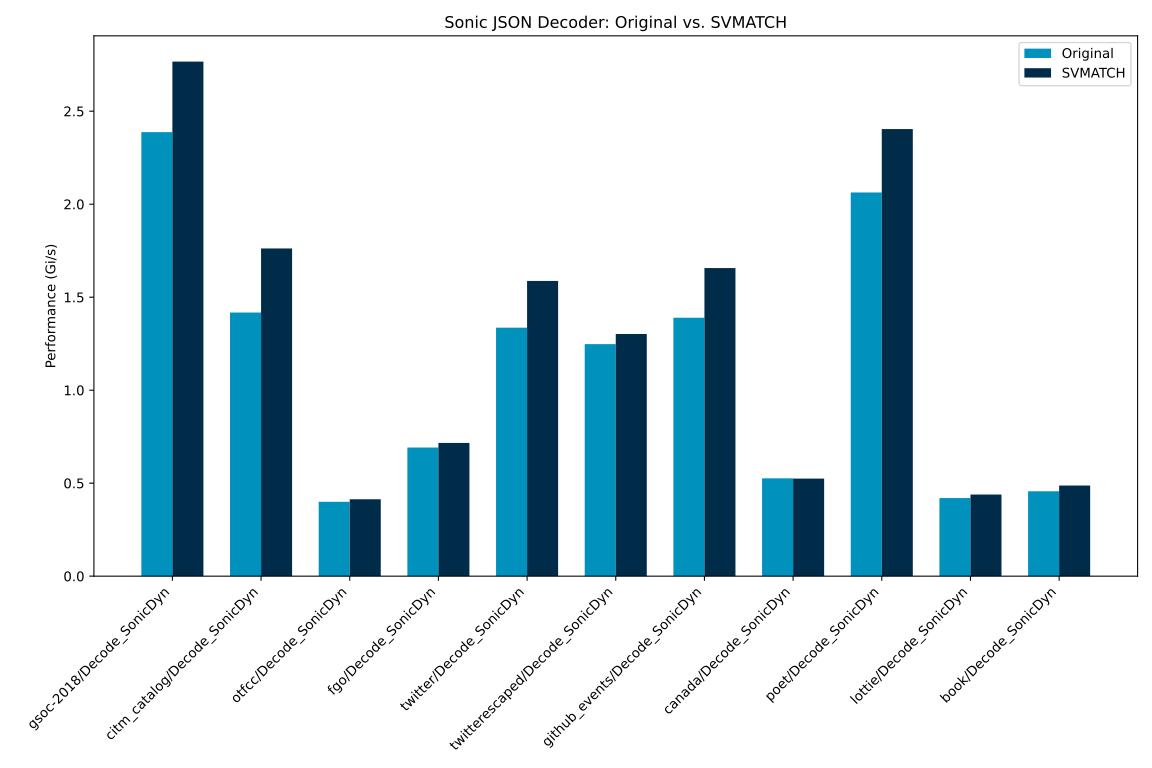
Comparison of Sonic JSON Decoder Performance
Upstream patch for reference: https://github.com/bytedance/sonic-cpp/pull/92

By Yibo Cai
Re-use is only permitted for informational and non-commercial or personal use only.
