Transforming smart home privacy and latency with local LLM inference on Arm devices
Learn how Raspberry Pi 5 and Arm-based local LLM inference can power a fully private, cloud-free smart home assistant with real-time performance

The problem: Smart homes rely on the cloud. At a cost.
Most smart home assistants rely on cloud-based AI. They use it even for simple tasks, such as turning on a light, setting a thermostat, or checking energy usage.This introduces privacy risks and lag. It also makes your home vulnerable to network outages.
In a world moving toward privacy and autonomy, the challenge is clear. Can we bring true intelligence to smart homes—locally, efficiently, and privately—using affordable hardware like Raspberry Pi 5?
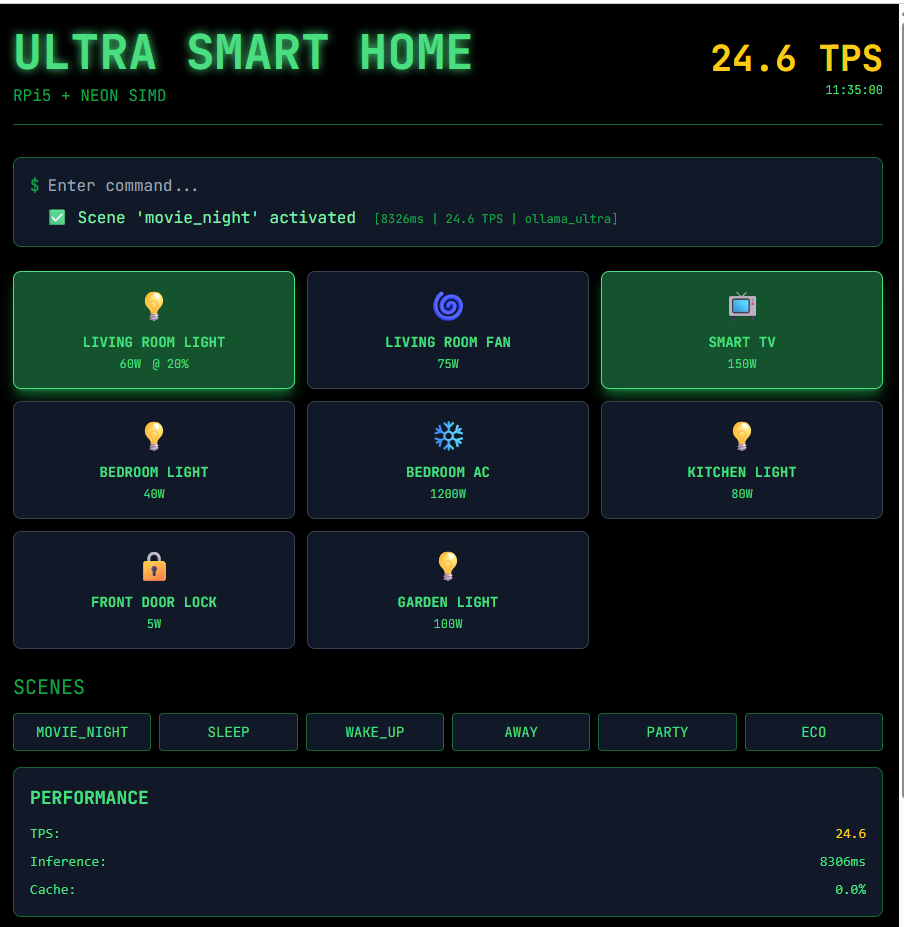
Figure 1: UI when running Qwen.
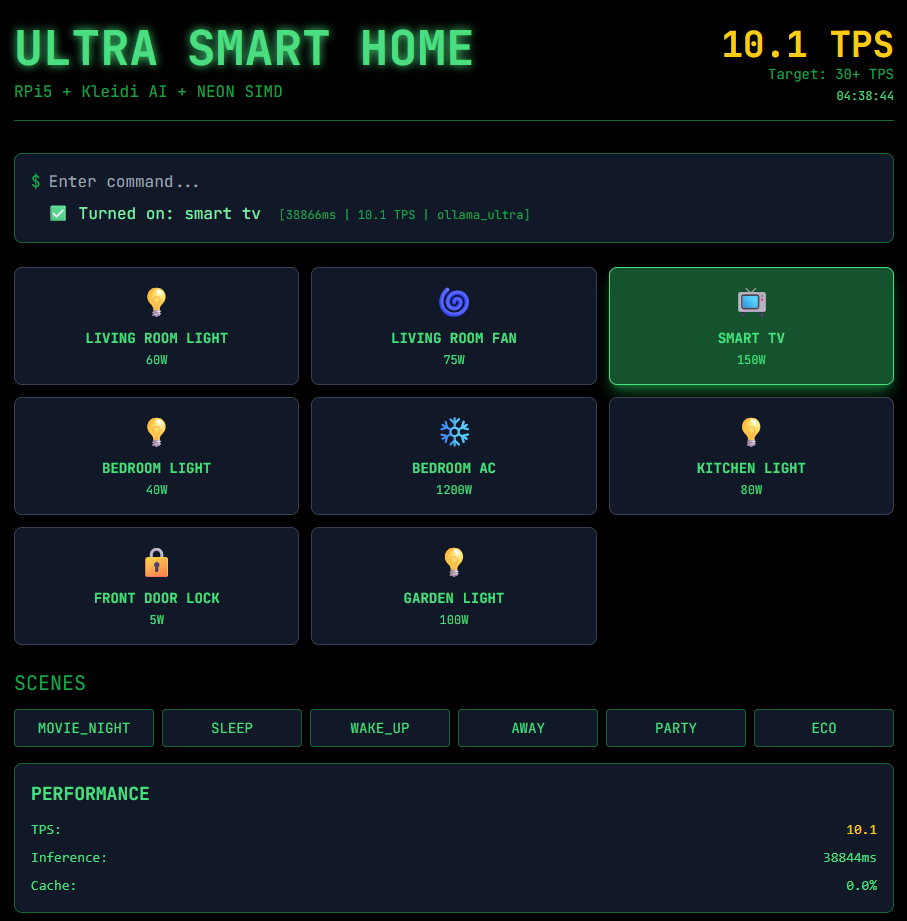
Figure 2: UI when running DeepSeek.
Why it matters: Privacy, reliability, and Edge AI for everyone
For millions of users, especially those with unreliable or costly internet a cloud-dependent smart home is only “smart” when the network works. Even in well-connected homes, privacy remains a growing concern. The Raspberry Pi 5 delivers a major performance leap with its 64-bit Arm processor. Paired with efficient LLMs, it can now run advanced AI locally, offering full privacy and real-time response. This project shows that powerful, private AI can now run on affordable, accessible hardware.
The solution: Private, conversational smart home AI on Raspberry Pi 5
This open-source, privacy-first smart home assistant shows that large language models can now run entirely locally on Arm-based devices. It uses Ollama and LLMs for natural language commands and home automation.. There is no cloud. There is no compromise.
Key implementation steps

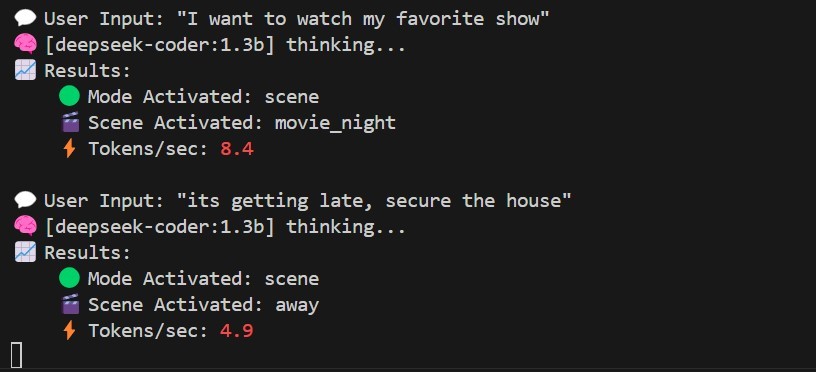
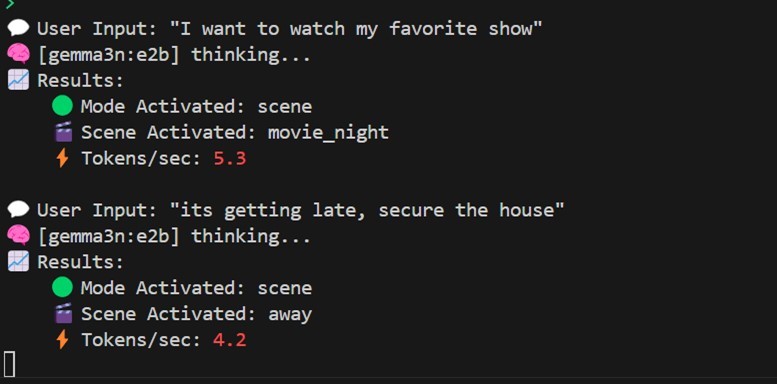
- Ollama LLM Backend: All Natural Language Processing (NLP) runs on-device using Ollama, supporting models like Deepseek, Tinyllama, Qwen, and Gemma. Models are pulled and run locally, requiring no external API.
- Optimized for Arm: The system is tuned for the Pi 5 quad-core 64-bit Arm Cortex-A76 processor. The architecture performance-per-watt efficiency and powerful NEON engine are essential for accelerating the complex mathematics of LLM inference, enabling the Pi 5 to run larger models with lower latency than previous generations.
- Direct Device Control: Supports GPIO, MQTT, and Zigbee for direct hardware integration with lights, fans, plugs, sensors, and more.
- Web Dashboard & API: Includes a clean UI and REST API for control and monitoring, plus a Command Line Interface (CLI) for advanced users.
- Real-Time Metrics: Monitors LLM speed (tokens/sec), command latency, power consumption, and cache hits—ensuring full transparency and performance tuning.
Hardware setup

Figure 3: Hardware setup
- Raspberry Pi 5 (8GB or 16GB recommended). This single-board computer features a quad-core Arm Cortex-A76 CPU, each core operating at up to 2.4 GHz. The Arm cores support NEON SIMD (Single Instruction, Multiple Data) extensions, enabling efficient parallel processing for optimized performance in compute-intensive applications.
- Raspberry Pi OS 64-bit (or Ubuntu 22.04 ARM64).
- MicroSD or NVMe Storage.
- Internet for initial setup (operates offline once deployed).
- GPIO devices: lights, sensors, etc. connected via GPIO/MQTT/Zigbee.
- Full setup & instructions on GitHub: https://github.com/fidel-makatia/EdgeAI_Raspi5/tree/main.
System architecture
The system employs a fully local workflow from command to action.
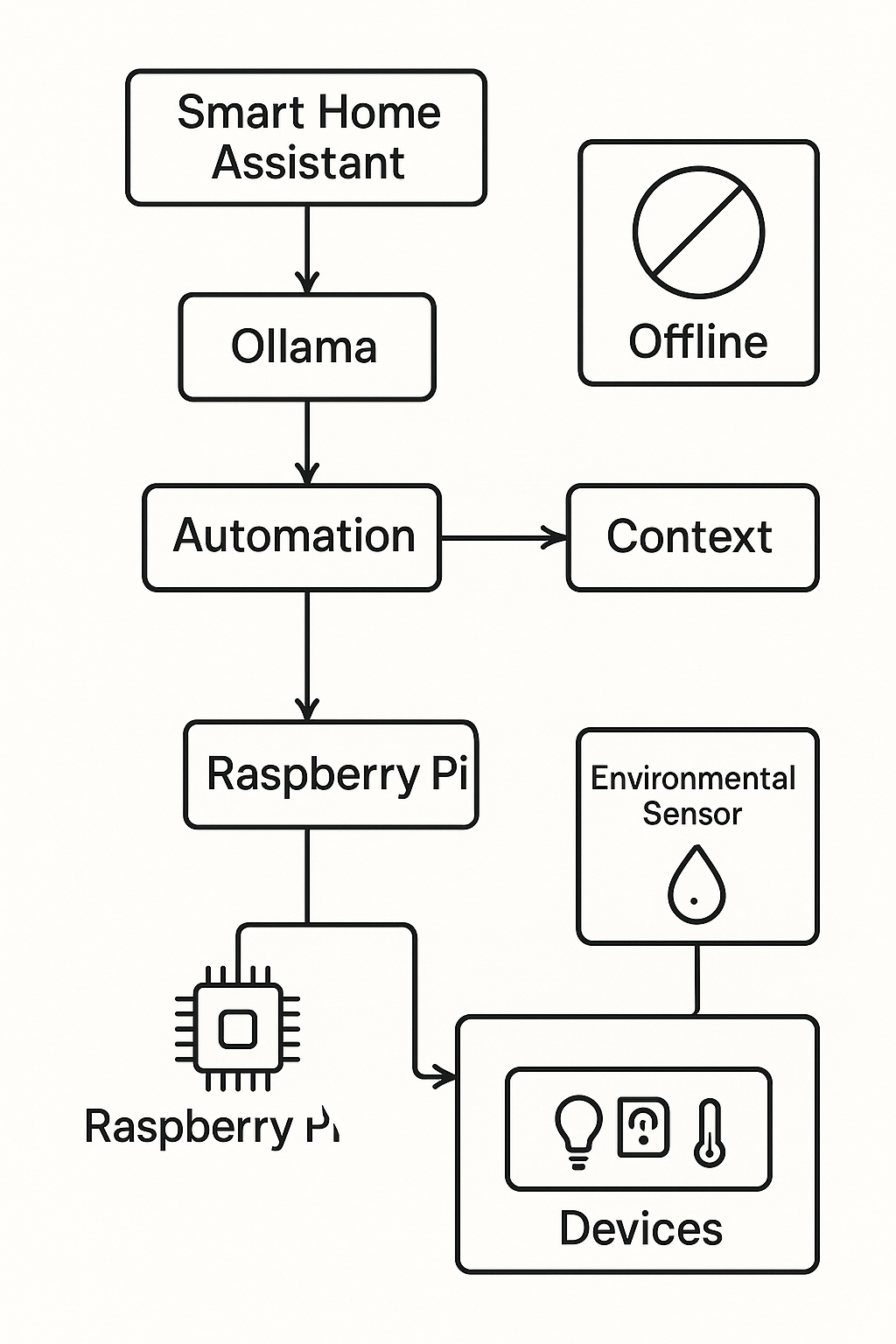
Figure 4: System architecture
Metrics visualization
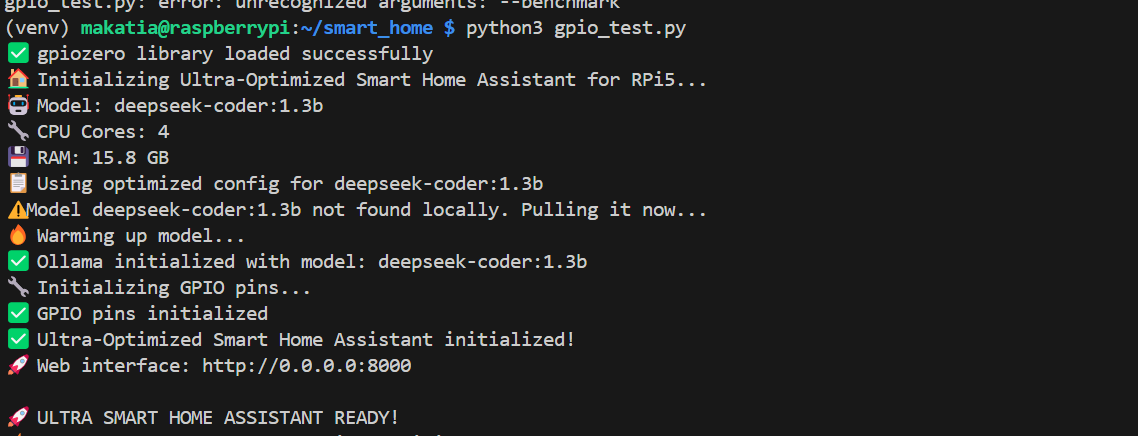
Figure 5: System initialization sequence highlighting key optimization steps and hardware/software initializations.
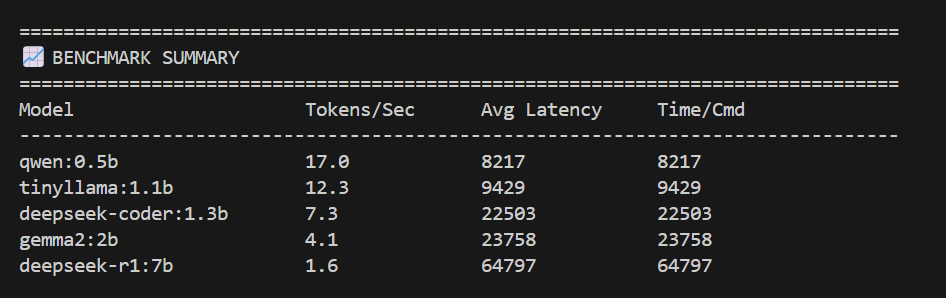
Figure 6: benchmark summary
Technical details
| Component | Details | Repo/docs |
| EdgeAI_Raspi5 | Main repo for local LLM inference and smart home integration on Pi 5 | https://github.com/fidel-makatia/EdgeAI_Raspi5 |
| Supported devices | Raspberry Pi 5 (Arm Cortex-A76) | |
| LLM backend | Ollama (DeepSeek, Gemma, Tinyllama, Qwen) | |
| OS | Raspberry Pi OS or Ubuntu Arm64 | |
| NLP interface | Ollama API (runs locally) | |
| Integration | GPIO, REST API, MQTT | |
| Frontend | Flask, HTML/CSS/JS Web Dasbboard | |
| Metrics | Token/sec, latency, device state, power draw |
Challenges and solutions
- Deploying LLMs on the Pi 5: Ollama’s quantized models make LLM inference practical. Quantization reduces the memory and computational footprint of models, a technique highly effective on modern Arm CPUs. This allows the Pi 5 to support models up to 7B parameters (e.g., Deepseek 7B) in under 16GB RAM.
- Maintaining Real-Time Responsiveness: All requests and automation remain local, resulting in sub-second response times for most tasks after inference.
- Universal Protocol Support: The code is modular to support GPIO, MQTT, and Zigbee, ensuring compatibility with a wide range of home hardware.
Performance metrics
|
Metric |
Local LLM on Pi 5 (Ollama) |
Cloud-Based AI |
Notes |
|
Inference Latency |
~1–9 sec (Tinyllama 1.1B) |
0.5–2.5 sec (+network jitter) |
Local is consistent, private, and predictable. |
|
Command Execution |
Instant after inference |
Delayed by network/server |
The Arm-powered Pi 5 eliminates the cloud as a point of failure. |
|
Tokens/Second |
8–20 tokens/sec |
20–80+ |
Local models are rapidly improving in speed on Arm hardware. |
|
Reliability |
Works offline; no external dependency |
Needs Internet |
The Pi 5 provides an always-on hub immune to ISP outages. |
|
Privacy |
100% on-device; nothing leaves |
Data sent to provider |
Absolute data privacy is guaranteed. |
|
Cost (Ongoing) |
$0 after hardware |
$5–$25/mo (API fees) |
No recurring costs. |
|
Model Customization |
Run any quantized model locally |
Fixed by provider |
GGUF and ONNX formats are supported for full flexibility. |
|
Security |
Local network only |
Exposed to remote breaches |
The attack surface is dramatically reduced. |
Results & impact
- Truly Local, Private AI: All processing and automation occur on-device—no data ever leaves your local network.
- Low Latency, High Reliability: Near-instant command execution—even with the internet unplugged.
- Hardware Flexibility: Runs on any Arm Cortex A architecture that supports Python and Ollama.
Technology stack
- Backend: Python 3, Flask
- Web: HTML, CSS, JS
- LLM/NLP: Ollama, DeepSeek (others: Gemma, Qwen, Tinyllama, Mistral)
- Hardware: gpiozero, Adafruit DHT (optional)
- API: REST, Web dashboard, CLI
Get started
- Repo & Docs: https://github.com/fidel-makatia/EdgeAI_Raspi5
- Quickstart:
- Flash Raspberry Pi OS or Ubuntu to an SD card/NVMe drive.
- Clone the repo & follow the installation instructions.
- Download supported LLMs using Ollama (see repo for tips).
- Connect home devices and automate.
What is next
- Fork the repo and try it on your own Pi 5.
- Extend for more models, protocols, or sensors.
- Use the dashboard for local automation and monitoring.
- Watch the demo below.
Watch demo
Arm developer tools used
Resources
- EdgeAI_Raspi5 GitHub: https://github.com/fidel-makatia/EdgeAI_Raspi5
- Ollama: https://ollama.com/
- Raspberry Pi 5 Documentation
- Whisper.cpp (for optional voice integration)
This project shows how local LLM inference on Raspberry Pi 5 transforms smart home privacy, latency, and reliability. It puts control where it belongs, at the edge.
For a step-by-step guide on creating a privacy-first smart home assistant, explore the Arm Learning Path for Raspberry Pi Smart Home.

Re-use is only permitted for informational and non-commercial or personal use only.
