Space Bartender: Using LLMs in Unreal NNE on Mobile CPU
Experience how fine-tuned LLMs and Arm KleidiAI power lifelike, mood-driven NPCs in Unreal Engine, bringing real-time emotion to mobile
By Bhanu Arya

Picture this: you step into a neon-lit bar in a distant galaxy. The air hums with the energy of open space, and behind the counter stands a robotic Bartender. You ask for a drink. Sometimes you get a polite smile, other times a sarcastic jab.
Either way, the reply feels alive, in-character, and straight out of a sci-fi story. That is the magic we set out to craft in this proof of concept with a Large Language Model (LLM). One big challenge remained: could we run an LLM directly inside Unreal Engine on an Arm CPU on-device?
Turning the problem into a plan
Most LLMs are too large, too generic, and too slow for on-device games. We needed something small, fast, and deeply in-character. That meant:
- Choosing the right small fast LLM.
- Teaching the LLM how to behave like a Bartender.
- Converting and compressing it so it could run smoothly on-device.
- Plugging it into Unreal Neural Network Engine (NNE).
The goal was simple: make Players feel like they are talking to an NPC who truly belongs in their universe, not just a chatbot.
The Space Engine – Unreal Neural Network Engine (NNE)
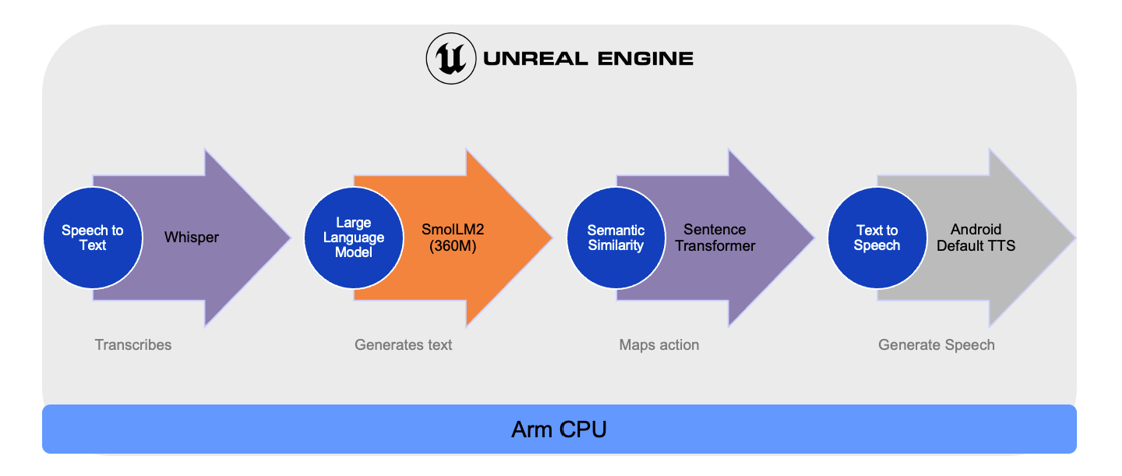
Model Inference Pipeline
Unreal NNE provides a common API for neural network inference across backends like ONNX Runtime. We used NNE with ONNX Runtime as the backend to run an LLM that will power the Bartender conversation.
For a Player talking at game runtime, the inference latency of the response must be low. This rules out the cloud and removes latency and monetary costs. On device, the GPU would normally be a great choice of accelerator, but in game it is fully occupied with the graphics pipeline. Therefore, we must run the LLM on the mobile's CPU.
To make this happen, a model pipeline takes in the Player’s voice. It processes it through a series of models and returns the Bartender’s voice, followed by its action. When the Player speaks, the Whisper speech-to-text model listens and transcribes the words into text. The transcribed text is passed to a lightweight LLM, SmolLM2, which figures out what the Bartender should say.
A Sentence Transformer model maps the text to the correct action. Finally, the response goes through text-to-speech, so you hear it back naturally using Android’s built-in voice. The best part is that all these models run directly on the CPU with ONNX models, making it portable and device friendly.
Both the LLM and the Sentence Transformer run on the CPU via NNE. We updated ONNX Runtime to version 1.22 to take advantage of Arm KleidiAI enabled performance optimizations which automatically unlock latest Arm technologies where present for accelerated GenAI on Arm CPU, such as Neon, SVE and SME.
Generating data to bartend with different moods
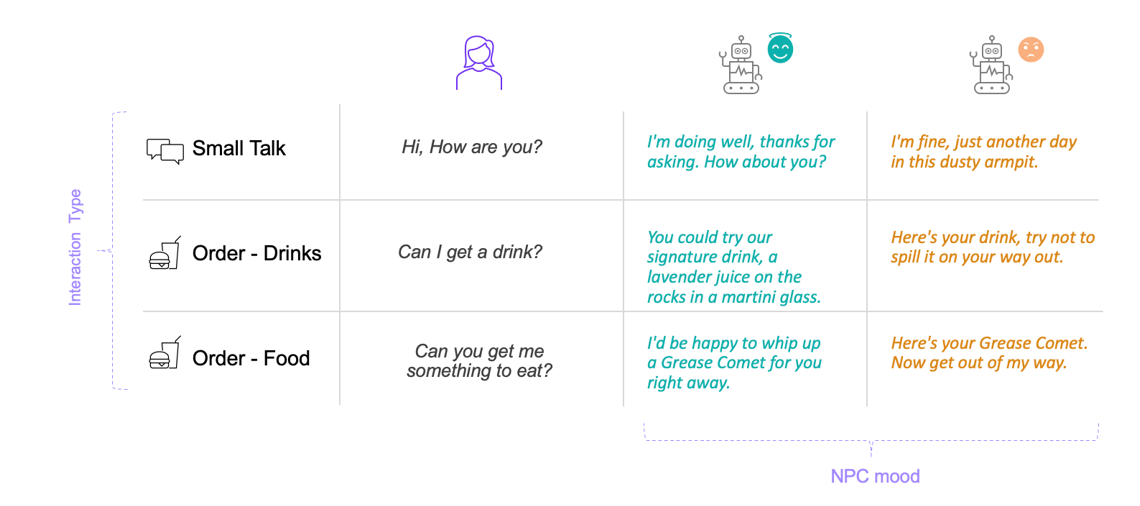
We want the LLM to respond like a Bartender. To add personality and engagement, the Bartender should respond according to different moods: ‘polite’ or ‘grumpy’. For this we require a dataset of Player-Bartender conversations with different Bartender moods. This enables the LLM to learn from these Player-Bartender interactions and generate realistic responses at runtime.
As no such dataset of space sci-fi Player-Bartender conversations exists, we created our own. We created a synthetic dataset by prompting OpenAI’s GPT4-o model to generate Player and Bartender conversations in a sci-fi space bar. First, we generated Player-Bartender interactions on various topics of small talk and food ordering in the ‘polite’ mood. For small talk we included topics like ‘greetings’, ‘conversation openers’, etc. and for ordering topics we include ‘indirect request’, ‘suggestive orders’, etc.
Secondly, for each Player-Bartender interaction, we isolated the Player messages. The GPT-4o model was then prompted to generate Bartender responses to each of the Player messages in a ‘grumpy’ mood. Using this two-step approach, we built 13,000 dialogues. For each Player request, the Bartender could produce either a ‘polite’ or ‘grumpy’ response, depending on the chosen mood setting.
Fine-tuning model to learn different moods
We chose a small open-source model, SmolLM2, a 360 million parameter instruction-tuned model. We then fine-tuned it with the Player-Bartender conversations dataset that we created. Training a smaller model was challenging because of its limited representational capacity compared with the larger multi-billion parameter model.
To address this, instead of retraining all the weights, we used parameter-efficient tuning with Low Rank Adaptation (LoRA). We trained a small set of low-rank matrices and then merged it with the original frozen model. This updated a small fraction of the model weights.
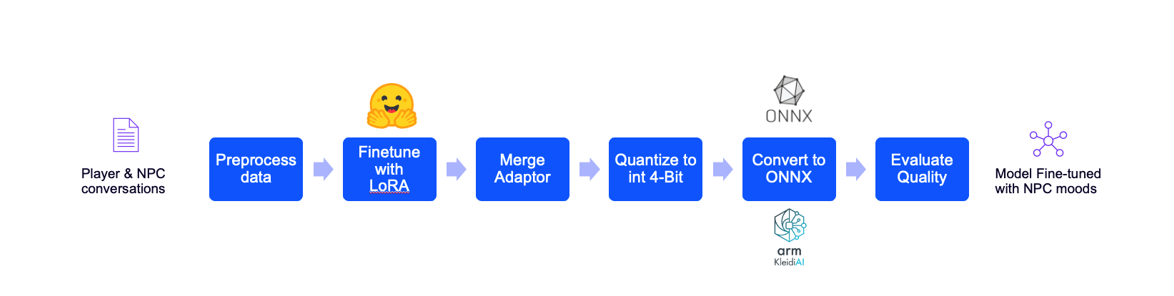
LLM Fine-tuning pipeline with ONNX model optimized by Arm KleidiAI
During the fine-tuning process, the system prompt was updated to reflect the same Bartender mood as is present in the training dataset for each sample. The mood was explicitly mentioned in the system prompt and implicitly observed in the Player-Bartender interaction. This enabled the LLM to learn of different moods and Bartender responses.
This method of dataset curation and LLM fine-tuning also enables programmatic control of the NPC mood at runtime. For example, after three repeated ‘polite’ responses, the Bartender mood can be switched to ‘grumpy’ by updating the system prompt. This change displays the NPC annoyance caused by repetition.
Before fine-tuning, the model did not generate a useful or accurate response for an NPC Bartender. After fine-tuning and updating the system prompt with a polite mood, the same prompt came back with: “A refreshing blend of cosmic delight awaits.”
In that moment, we knew we had given the bartender a voice.

Polite and Grumpy modes of Bartender, generating appropriately different responses.
Even a fine-tuned model can be heavy. To run it in a real game, we quantized the model weights to 4-bit integer and converted it into the ONNX format. This reduced the model size from 1.45 GB to 388 MB. This made it possible to run locally inside Unreal NNE, and keep the APK size down, as we will need plenty of room for other game assets.
While NNE provides an interface for running an arbitrary ONNX model, we still had to implement additional LLM-specific features, such as tokenization, KV-caching and output sampling. We did this through Unreal’s C++ API, exposing relevant parameters to Unreal Blueprints to make the overall development pipeline easier. This was challenging to implement as it required a deeper understanding of the internal workings of an LLM. However, we had the right tools to build on top of NNE to get a working on-device LLM.
From version 1.22, ONNX runtime, which is being used as a backend for NNE, has support for Arm KleidiAI. This allows us to make the most of Arm CPU technologies on mobile devices. In this case it gave us a 2.3x speedup in the prefill stage, which significantly reduces the time-to-first token giving rise to a fluid response.
|
|
Prefill Speed (tokens/second) |
Decode Speed (tokens/second) |
|
With Arm KleidiAI |
565 |
45 |
|
Without Arm KleidiAI |
249 |
44 |
Model inference was optimized by compiling the ONNX models with Arm KleidiAI. It reduced the latency between a Player asking for a drink and receiving a Bartender reply by half. This improved users’ real-time gaming experience, entirely on-device. Suddenly, the Bartender was ready to serve you a drink.
Bringing the NPC to life with actions
When we integrated the model into Unreal, the bartender didn’t just talk, it acted. A ‘polite’ request like “Can I get a drink please?” comes back with a response “Sure thing, here’s a refreshing highball with lemon” and the Bartender makes the drink. In contrast, when ‘grumpy’ mood is selected, it responds, “Here’s your drink, try not to spill it on your way out” and still makes the drink even with the less informative grumpy response.
Behind the scenes, a mood is selected for the NPC response and added to the LLM’s system prompt. We concatenate the Player request and Bartender response and convert to sentence embeddings using a Sentence Transformer model. These embeddings are then compared to a list of predefined possible interaction-action pairs in a lookup table. Based on the semantic similarity, the interaction is matched to an action. For this matched interaction-action an event action is chosen. This instructs the NPC to perform the corresponding action, such as preparing and serving a drink on-screen, after generating a response to the Player.
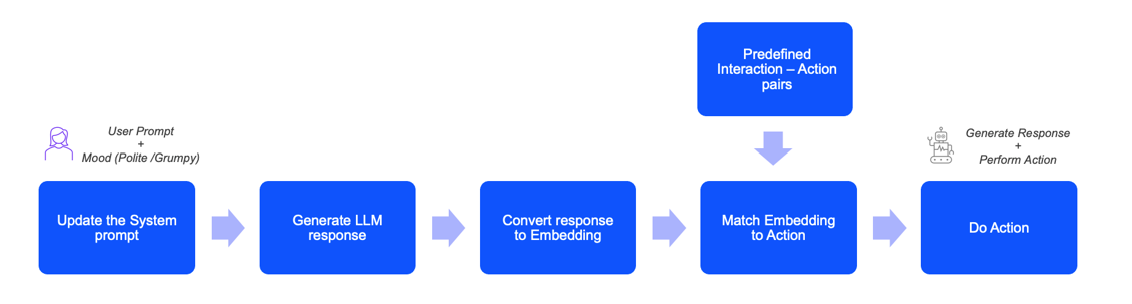
LLM Inference Pipeline with response-action mapping
The use of generative AI (GenAI) at runtime is a game changer. It makes characters feel more lifelike, deepens immersion, and creates unique player experiences that scripted dialogue cannot match.
Last year our team showcased verbally interaction of NPCs on mobile and the future of player-NPC interaction powered by LLM. This time we extended the work further to show how we can control the mood of the NPCs at real time creating more realism to the game while improving user experience.
This project shows how fine-tuned and optimized LLMs can live entirely on-device and power richer NPCs with different moods. By running on ONNX Runtime, optimized for CPUs with Arm KleidiAI, inside Unreal NNE, we proved that intelligent, responsive characters can exist right where the game does, on mobile. In our case, that meant building a bartender who is as much a character as any hero or villain in the story.
Learn more how to use AI in game development and develop LLM based NPCs responsibly. This is only the beginning. We are already exploring new scenarios where GenAI will make gameplay even more dynamic and fun.
Use AI in game development Develop LLM based NPCs responsibly

By Bhanu Arya
Re-use is only permitted for informational and non-commercial or personal use only.
