Vulkan subpasses: the good, the bad, and the ugly
Understand when Vulkan subpasses improve efficiency, when they do not, and how modern Arm GPUs close the gap.
By Peter Harris

Vulkan subpasses provide useful optimization opportunities for tile-based GPUs but can also cause unexpected performance side-effects that catch developers out. This blog post explores the pros and cons of subpasses in more detail, helping you to understand what to expect when using them.
What are subpasses?
Vulkan defines a render pass as a container for rasterization workloads. In the original Vulkan 1.0 definition, a render pass is a sequence of one or more subpasses. Each subpass defines a set of input and output framebuffer attachments. A fragment shader in one subpass can read the output value from an earlier subpass at a matching sample coordinate.
Subpasses provide an abstraction that supports optimizing memory bandwidth when using tile-based GPU hardware. Attachment data exchanged between subpasses can be kept inside on-chip tile memory until no longer needed, and then be discarded.
The good…
Deferred lighting is a common algorithm that can benefit from subpass optimization. Traditional deferred lighting renders opaque object lighting using two render passes. The first render pass collects material data for each fragment using a multiple-render target Geometry buffer (G-buffer). The second render pass computes the lighting, reading material data from the G-buffer textures as the primary inputs to the lighting equation. This pass iterates over all lights to accumulate the contribution from each light source.
Without subpasses, this involves writing the G-Buffer back to memory after the first render pass and reading it back in again during the second. A G-buffer can consume 128-bits per pixel of color data, and sometimes more, so this round-trip through main memory consumes a lot of memory bandwidth. Accessing DRAM is energy intensive, making this an expensive technique to use, especially on battery powered mobile devices.
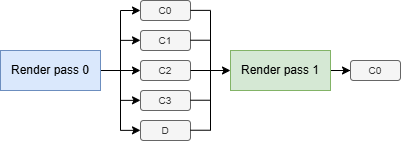
With subpasses, you can use a single render pass made up of two subpasses. The G-buffer is stored in tile memory during the first subpass and read directly from tile memory during the lighting calculations in the second subpass. The G-buffer attachments can be discarded at the end of the render pass when they are no longer needed.
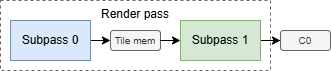
Using tile memory like this avoids the major DRAM bandwidth cost of deferred lighting and improves battery life and device thermals for mobile gaming. So subpasses sound great, but what is the catch?
The bad…
Subpasses are a standard Vulkan API feature and are always available. However, whether subpasses merge into a single hardware render pass and exchange data via tile memory depends on the implementation. The optimization depends on the hardware, the driver, and the precise API configuration used for each subpass.
All Arm GPU Vulkan implementations are capable of merging compatible subpasses. However, some OEMs disable subpass merging in the driver for older GPUs because of the performance loss it can cause for some content. This makes subpasses unpredictable to use, which is never ideal for an application developer.
Note: As far as Arm is aware, no OEMs have disabled subpass merging on devices with a Mali-G710 series GPU, or later.
The VK_EXT_subpass_merge_feedback extension provides feedback about if, and how, subpasses merged on a specific device. This lets you confirm that the expected merging is occurring when you expect it to. We first introduced this extension in the r38p0 driver, and it is now widely available.
The ugly…
Subpasses can reduce memory bandwidth, but it is worth noting that they do not necessarily improve clock-for-clock performance. For Arm GPUs, peak texture performance is always at least as fast as the performance of tile memory access. Swapping texturing for tile reads gives no direct performance benefit unless you hit a system bandwidth limit or thrashing the texture cache. A good result for using subpasses is keeping performance the same, but with significant memory bandwidth reduction.
The “ugly” part of this story is that subpasses might be slower in terms of clock-for-clock performance than not using subpasses. This is because a render pass with merged subpasses is a more difficult workload for the GPU to schedule. This may not be a problem for many applications, and the bandwidth savings will bring energy efficiency savings, but it is often unexpected. Let us look at why this happens.
GPU queue scheduling
The first performance impact comes from the coarser schedule implied by the merged render pass. Arm GPUs are tile-based and must complete all geometry binning for a hardware render pass before they can start fragment shading it. Merging subpasses increase the initial geometry workload and delays the start of fragment shading. Depending on timing and scheduling of other GPU work from the application, it may not be possible to hide the added latency.
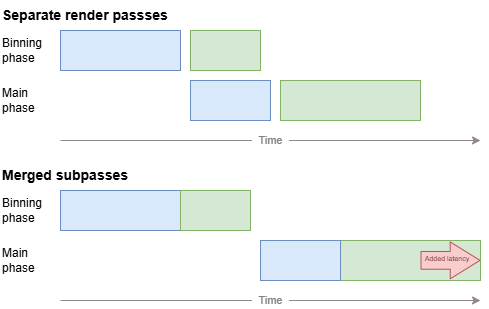
Recent GPUs, starting with the Immortalis-G920 series, improve the performance of the initial vertex shading and tile binning workload. The application-visible impact of an exposed serial binning phase is reducing over time, and further improvements to this are expected in future hardware generations.
GPU warp scheduling
The second performance impact comes from scheduling dependencies inside the shader core during tile processing. A fragment shader reading a value from tile memory must wait for earlier layers to write the value and will stall until it is available.
In Mali GPUs before the Mali-G710 series, the shader core only has a single dependency tracker per pixel. A fragment cannot access tile memory until all older fragments at its location have completed their tile memory accesses. This results in pessimistic scheduling and false dependencies for multi-attachment usage. The GPU can run out of warps to run because many are blocked waiting for earlier layers to complete.
The diagram below shows the impact on scheduling three layers that each access three locations in tile memory. The red bars show the shader trying to read or write a tile memory location in the G-Buffer. Each layer stalls on its first access attempt to tile memory, blocking until it becomes the oldest layer.
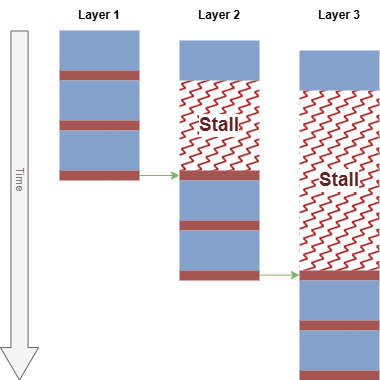
Since the Mali-G710 series, Mali shader cores have multiple framebuffer dependency trackers per pixel. This allows dependencies to be released incrementally as a shader progresses. This change improves performance in use cases such as deferred lighting, where each shader accesses multiple attachments.
The diagram below shows the updated schedule for the same three-layer example. None of the layers stall. When a layer reaches the synchronization point for a specific location in tile memory, the previous layer has already completed its operations that release that dependency.
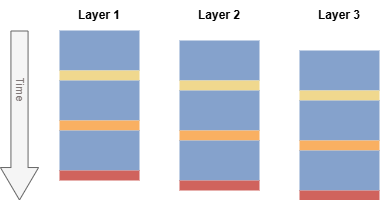
In addition to the improved dependency tracking, the Mali-G710 series also switches to larger 32x32 pixel tiles. This reduces layer-based stalls because the shader core can be filled by running warps at more unique pixel locations. The core is less reliant on running spatially overlapping warps with dependencies.
Shader core functional unit throughput
Tile memory reads use a different functional unit in the shader core than texture reads. Since the Mali-G77 series, the first of the Valhall architecture family, texture sampling is twice as fast as tile memory access.
If tile access is already heavily loaded by a render pass, changing to use merged subpasses may be slower than reading a texture. This is uncommon in real content, but it is something to be aware of if your shaders are very simple.
Shader core cache impact
When running merged subpasses each tile must cycle through more unique resources, such as shader code, buffers, textures, to complete its processing. The increased number of resources in each tile increases pressure on the shader core caches. This can reduce performance if cache thrashing occurs under high resource pressure.
Shader core optimization impact
Mali GPUs include optimizations that can skip unnecessary work when appropriate. The empty tile elimination optimization can skip tiles with no geometry, including the loadOp=LOAD readback behavior for the render pass. The transaction elimination optimization can skip writing the COLOR0 attachment for a tile, even if the storeOp is STORE. Subpasses can change how these two optimizations trigger.
For example, consider a case without subpasses where there are two render passes running serially. Render pass 0 includes geometry that only partially covers the screen. Render pass 1 renders a full-screen quad that reads the output of Render pass 0 as a texture. Render pass 0 uses loadOp=LOAD for color and depth, and both render passes write to their respective COLOR0 output attachment.

When not using subpasses, Render pass 0 will trigger the empty tile elimination optimization because it only has partial geometry screen coverage. Both passes trigger transaction elimination if the tile content is unchanged, because each writes through the COLOR0 hardware attachment point.
When subpasses are merged into a single hardware render pass, the mapping could look like:

This ends up disabling both optimizations in this scenario:
- Empty tile elimination will no longer trigger because subpass 1 contains a full screen quad. This means every merged tile in the hardware render pass now contains some geometry. Subpass 0 must execute for every tile, including performing the loadOp=LOAD for any specified input attachments.
- Transaction elimination will not trigger for the final output attachment because it has been remapped to the COLOR1 hardware attachment slot. Only COLOR0 supports triggering transaction elimination.
These optimizations are not expected to trigger for 3D game rendering. However, we have seen these issues manifest in simple test scenes that only render a few objects and create a static unchanging image every frame. These tests can make the non-subpass scenario appear artificially better because both optimizations trigger more often than they would in a real gameplay scenario.
Modern alternatives
Vulkan is moving away from subpasses as the abstraction around tile memory. The new style of dynamic render passes introduced in Vulkan 1.4 subpasses no longer exist. However, optimizing algorithms by using tile memory is still possible using extensions that allow explicit programmatic shader access.
The VK_EXT_rasterization_order_attachment_access extension provides Vulkan 1.0 style render passes with explicit shader-based access to attachments. This is supported since the r36p0 driver (for the ARM extension) or the r40p0 driver (for the EXT extension).
The VK_KHR_dynamic_rendering_local_read (DRLR) extension, which was made part of the core specification in Vulkan 1.4, provides dynamic render passes with explicit shader-based access to attachments. This has been supported since the r49p1 driver. A similar extension, VK_EXT_shader_tile_image, as been available since r44p1 driver. This extension has been superseded by DRLR, which should be used instead when available.
These explicit shader access extensions are guaranteed to map onto tile memory for Arm GPUs. This avoids the variability caused by the implementation-defined merging behavior of subpasses. However, the same performance caveats that impact subpasses will also impact use of these extensions because the underlying hardware is the same.
Summary
Reducing memory bandwidth is a key goal for mobile rendering, and Vulkan subpasses are one way to achieve that. However, subpass optimization depends on implementation-defined behavior and can reduce clock-for-clock performance in some cases. This may not be a problem if application performance targets are still met and energy efficiency improves. Recent Arm GPUs reduce the performance gap, and we will continue to improve this in future products.
Modern Vulkan uses a new dynamic render pass abstraction that no longer supports subpasses. Optimizing using programmatic access to tile memory is still possible using new extensions that provide direct shader-based access to framebuffer attachments. The dynamic rendering local read extension was made part of the core specification in Vulkan 1.4.
Frequently Asked Questions
Q: Are subpasses always beneficial to performance?
A: If subpasses merge they will nearly always save memory bandwidth and that helps energy efficiency. However, there is no reason why merged subpasses should be faster than non-merged subpasses unless you are memory bandwidth limited. Indeed, due to the caveats presented here, performance is often slightly reduced, especially on older GPUs.
The reduction in bandwidth can indirectly increase performance. Improved energy efficiency might allow the GPU to run at a higher clock frequency while staying within the thermal limits of the device.
Arm recommends that you always profile content using subpasses, especially on older devices, to check that it is beneficial for your use case. You can do this using our Streamline profiler, which is part of the free to use Arm Performance Studio.
Q: Do explicit alternatives to subpasses avoid performance issues?
A: No. The modern shader-based extensions avoid the uncertainty of implementation-defined subpass merging, but they are fundamentally expressing the same algorithmic intent to the same underlying hardware. Performance loss caused by underlying hardware scheduling differences should be the same in both cases.
Q: How can I tell if subpasses merged?
A: At the API level, you can use the VK_EXT_subpass_merge_feedback extension to query when a render pass is created.
When profiling using the Arm Streamline profiler, which is part of Arm Performance Studio, you can see the effect of subpass merging in two ways:
- As a direct measure, the Mali timeline scheduling trace will show the hardware render passes that were performed. You will be able to see how many hardware render passes were scheduled for each API render pass you submitted. This is a relatively new feature that requires a CSF GPU and r51p0 or newer drivers, although a subset of devices shipping with r49p1 drivers included it as a technology preview.
- As an indirect measure, the Mali performance counters can measure the pixel count written by hardware render passes. When using subpasses that merge you should see a reduction in pixel count when compared to a build using separate render passes.
Q: Which devices disable subpass merging?
A: Arm does not have visibility of driver modifications used by OEMs, so we do not maintain a complete list.
Q: Is there any reason to use VK_EXT_shader_tile_image?
A: The VK_EXT_shader_tile_image extension was available earlier than VK_KHR_dynamic_rendering_local_read, so you can use it on more devices. However, when available, we recommend using dynamic rendering local read because this is now core functionality and available cross-vendor.

By Peter Harris
Re-use is only permitted for informational and non-commercial or personal use only.
