Accelerating AI-driven retrieval-augmented generation (RAG) pipelines with Arm Performix
Optimize RAG workloads on Arm with Performix, using profiling insights to tune BLAS performance and improve efficiency on Neoverse platforms.
Generative AI is shifting toward sophisticated Retrieval-Augmented Generation (RAG) systems. Infrastructure must seamlessly handle complex text processing alongside high-throughput matrix mathematics. This use case explores how Arm Performix empowers developers to maximize the efficiency of RAG simulations on Google Cloud’s Arm-based N4 instances. By providing deep visibility into the interaction between high-level Python logic and the underlying Neoverse architecture, Arm Performix enables precise hardware-level tuning that ensures AI workloads run at peak performance on the Arm ecosystem.
The challenge: optimizing retrieval-augmented generation (RAG)
In a cloud-based RAG environment, latency is the ultimate metric. To achieve sub-second response times, the system must efficiently handle two primary compute phases:
- Data Ingestion: Large-scale text chunking and SHA-256 integrity verification.
- Vector Similarity Search: Calculating similarity scores across multi-dimensional arrays using floating-point operations.
The goal is to use Arm Performix to validate the efficiency of Arm Neoverse N4 cores. This shows how developers move beyond software abstractions and confirm that math kernels use the hardware fully.
Methodology: developing the high-throughput workload
To simulate a production AI environment, I developed a Python workload that tests the multi-functional strength of the Arm64 processor.
Scalable text processing
The document chunking simulator uses Arm64 integer units for SHA-256 signature generation. This demonstrates that the CPU handles data ingestion efficiently with minimal overhead.
Precision vector search simulation
- The NumPy-based matrix multiplication routine targets high throughput on the Arm architecture:Dimensions: 1000 x 1000 matrices.
- Operation: numpy.dot() with floating-point operations.
- Profile: Iterative execution to allow Arm Performix to capture high-resolution performance data during sustained AI workloads.
Technical execution: streamlining the workflow
Profiling on Arm Neoverse instances provides precise performance data. During setup, the workload complied with PEP 668 to complete deployment.
- The insight: Arm Performix acts as a central tool for performance analysis and orchestration.By understanding the environment’s security boundaries, developers can use Performix to establish repeatable, optimized profiling environments. Thisensures that every AI deployment is tuned for the specific Arm microarchitecture from the start.
Key insights: maximum visibility with Arm Performix
Hardware-level symbol resolution
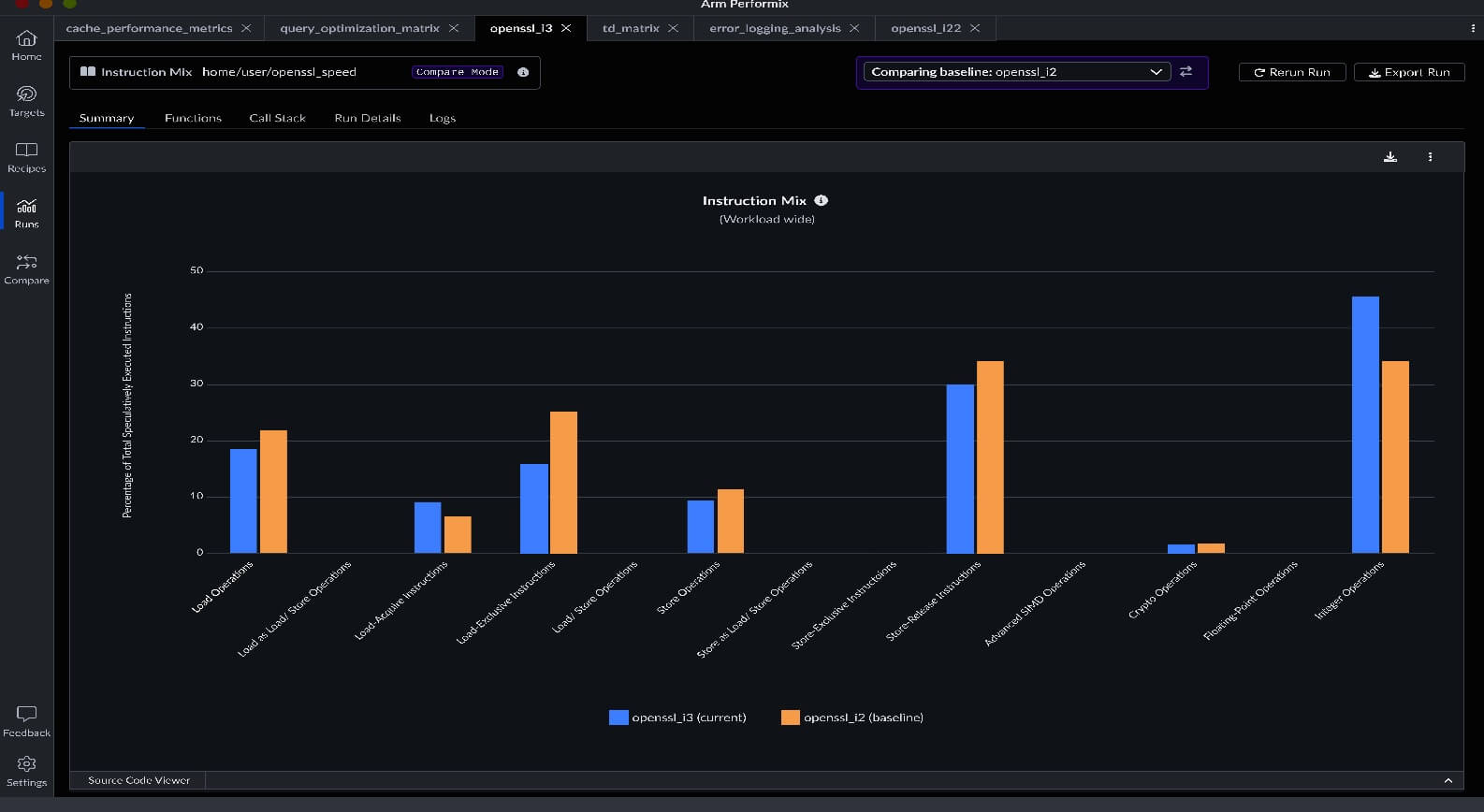
The greatest benefit of Arm Performix is its ability to map high-level code to hardware execution. The CPU Cycle Hotspots recipe identifies interactions between the Python script and the underlying libblas.so.3.11.0.
- The discovery: The tool identifies dgemm_ (double-precision general matrix multiply) function as a primary area for optimization, representing 22.46% of system cycles. This level of detail allows developers to see exactly where the Arm Neoverse cores are delivering the most value.
Architectural clarity with flame graphs
The Flame Graph provides a clear view of the call stack. The graph shows the transition from the Python main_workload through the C-extensions and into the optimized BLAS libraries, whichshows how execution moves from Python to lower-level libraries.
Temporal accuracy
The Arm Performix timeline shows system activity over time. The timeline shows changes in workload intensity over time. It indicates how theArm Neoverse N4 cores responds to load variation, maintaining low latency even under fluctuating AI demands.
Benefit & impact: the Arm advantage
This use case demonstrates how Arm Performix is a powerful catalyst for AI performance. The analysis shows that 22.5% of cycles are spent in core math functions. This indicates that optimizing the BLAS backend, for example with Arm Performance Libraries (ArmPL), can improve efficiency.
ArmPL is engineered to leverage SVE (Scalable Vector Extensions) or NEON instructions, allowing RAG pipelines to achieve massive throughput gains. Arm Performix provides visibility into how code uses hardware resources. This helps evaluate performance and efficiency on Arm architectures.
Phase 2: quantifying success
The next stage compares baseline performance with ArmPL and measures the impact. It documents the results to guide developers who want to optimize RAG pipelines on Arm.
Links to code, repos, or further reading
Official Arm resources:
- Arm Performix for Neoverse: Arm Performix: Analyze and optimize workloads on Arm Neoverse
- Arm Performix install guide: Arm Performix Install Guide
Pascal Mudimba is the Co-founder and CTO of stdio x labs, specializing in scalable cloud architectures and real-time data platforms. Bridging his passion for high-performance systems with aviation, he is currently pursuing his Flight Dispatcher license and ATPL ground school at the Kenya Airways Pride Centre.
Re-use is only permitted for informational and non-commercial or personal use only.
