How SiteMana scaled real-time visitor ingestion and ML inference by migrating to Arm-based AWS Graviton3
Migrating to Arm-based AWS Graviton3 improved SiteMana’s scalability, latency, and costs while enabling real-time ML inference at scale.
By Peter Ma

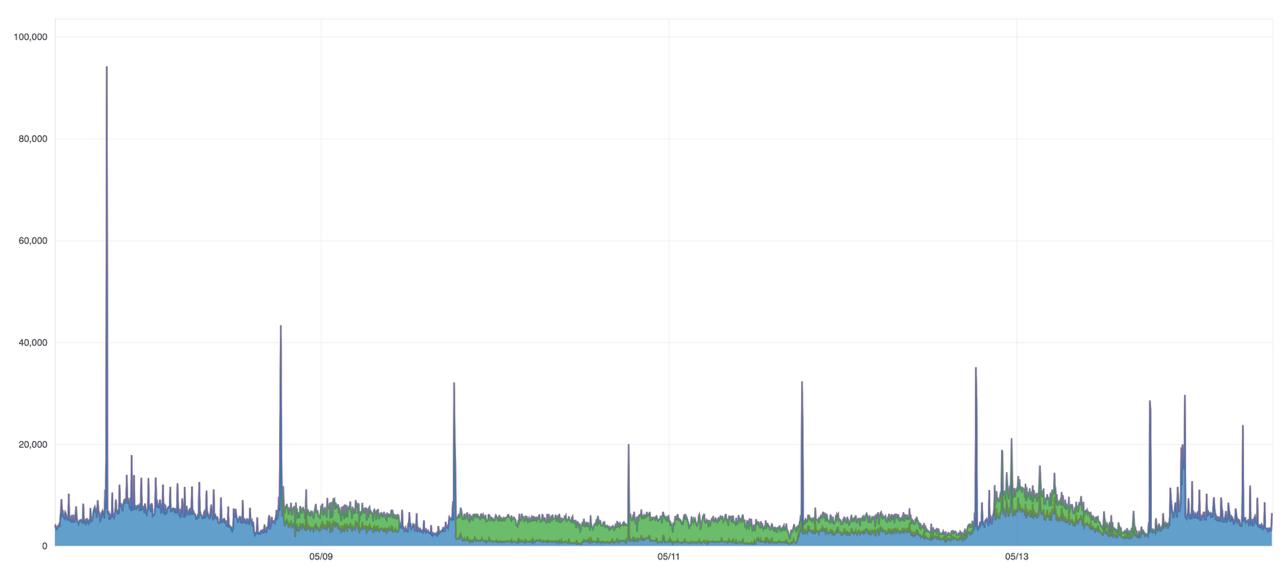
When SiteMana onboarded a large new publisher, our infrastructure load increased exponentially overnight. Each visitor page view flowed directly into our real-time ingestion pipeline. This rapid traffic caused CPU credits to quickly exhaust on our AWS x86-based t3.medium instances. As a result, performance was throttled at the exact moment we needed stability most. We quickly realized our system was not just scaling, it was breaking.
Why it matters: Real-time responsiveness and cost predictability
SiteMana needed a solution to manage 20–100 million daily visitor events. It also had to scale efficiently and support real-time TensorFlow inference to predict user purchase intent.
SiteManaprovides identity resolution and real-time purchase-intent prediction for e-commerce brands and publishers. Any delay in processing translates causes lost opportunities and revenue. Unpredictable CPU costs from AWS credit overages made budgeting difficult. This also affected operational efficiency.
Our solution: Migrating to Arm-based AWS Graviton3
We migrated our real-time ingestion and ML inference workloads to Arm-based AWS Graviton3 (m7g.medium) instances. Arm provides a CPU architecture optimized for consistent performance, predictable costs, and improved network throughput.
Steps we followed
- Deploy Arm instances alongside existing x86 instances behind an AWS Application Load Balancer (ALB).
- Route live traffic to both architectures to compare performance.
- Shift traffic gradually to Arm-based instances after validating compatibility and performance.
- Consolidate ingestion and inference workloads onto a unified Arm instance type.

Technical details
- Cloud Provider: AWS EC2
- Previous Instance: x86-based t3.medium (2 vCPU, 4 GiB RAM, 5 Gbps network bandwidth)
- New Instance: Arm-based AWS Graviton3 m7g.medium (1 vCPU, 4 GiB RAM, 12.5 Gbps enhanced networking)
- Operating System: Ubuntu 22.04 LTS (arm64)
- ML Framework: TensorFlow 2.11 (Arm-compatible binaries)
- Application Stack: Node.js v20, Express.js, Docker multi-arch containers
- Optimizations: Arm Neon SIMD instructions, TensorFlow thread tuning
- Monitoring Tools: AWS CloudWatch, Compute Optimizer
Challenges and solutions
Challenge: Ensureruntime compatibility across architectures.
Solution: Use AWS ALB to route incremental live traffic to Arm instances. Validate compatibility and performance parity without downtime.
Challenge: Reduce latency concerns with TensorFlow inference.
Solution: Optimize TensorFlow batch sizes and threading configurations. Use Arm Neon SIMD instructions to reduce latency and outperform x86.
Impact: Immediate and measurable results
After migration, SiteMana experienced significant operational improvements:
- Eliminate CPU credit throttling.
- Increase per-instance network bandwidth from 5 Gbps to 12.5 Gbps (2.5x improvement).
- Reduce TensorFlow inference latency by 15%.
- Reduce monthly infrastructure costs by around 25%.
- Consolidate workloads into a simpler, more manageable architecture.
Comparison table
x86 (t3.medium) vs Arm (m7g.medium)
| CPU Architecture | x86 (variable performance via credits) | Arm (consistent sustained CPU) | Predictable, no throttling |
| vCPU Count | 2 | 1 | More efficient CPU usage |
| Network Bandwidth | 5 Gbps | 12.5 Gbps | 2.5× increase |
| CPU Credit Throttling | Frequent under load | None | Eliminated completely |
x86 (t3.medium) vs Arm (m7g.medium)
| Inference Latency (p95) | 29ms | 25ms | 15% faster inference |
| On-demand Cost (hourly, USD) | $0.0416 | $0.0408 | ~2% lower per hour |
| Monthly Infrastructure Cost (20 instances, 100M events/day) | $800 (with credit overages | $596 (no credit model) | ~25% monthly savings |
| Infrastructure Complexity | Separate instances for ingestion & ML | Single instance for both workloads | Significant simplification |
What is next: Continuing to optimize and share insights
Our success with Arm-based AWS Graviton3 has led us to further other Arm-based architectures for other services and workloads. We encourage others considering similar transitions to begin testing and evaluate the benefits directly.
Code, repository & resources
- GitHub Repository: https://github.com/sitemana/arm-ingestion-ml-sample
- Arm Developer Tools Used:
- TensorFlow.js (Node.js bindings) – For efficient ML inference optimized for Arm.
- AWS Graviton Documentation – Overview and performance guidance for AWS Arm-based instances.
- Docker Multi-Architecture Builds – Essential for creating images compatible with Arm architectures.
- Arm Developer Tools Used:

By Peter Ma
Re-use is only permitted for informational and non-commercial or personal use only.
