Improve etcd performance up to 18% by deploying on AWS Graviton2
This blog looks into the performance and latency benefits of running etcd on AWS Graviton2 compared to equivalent 5th generation x86-based instances.
By Ker Liu

|
|
Introduction
etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. Most notably, it manages the configuration data, state data, and metadata for kubernetes, the popular container orchestration platform.
An etcd cluster is meant to provide key-value storage with best of class stability, reliability, scalability, and performance. Throughput and latency are some of the most common ways to measure performance. Latency is the time taken to complete an operation. Throughput is the total operations completed within a given time period.
In this blog, we compare the throughput and latency of etcd on two Amazon EC2 instance families across a range of instance sizes. These instance families are the Amazon EC2 M6g (based on Arm Neoverse powered AWS Graviton2 processors) and the Amazon EC2 M5 (based on Xeon Platinum 8000). Our results demonstrate achieving up to 18% performance benefits for etcd deployments on M6g instances compared to M5 instances. The following sections cover the details of our testing methodology and results.
Benchmark setup and results
For benchmark setup, we used the default benchmark CLI tool integrated within etcd project, which is the official benchmarking tool for etcd clusters.
Performance tests of etcd usually have two types of “put” workloads:
- write to leader
- write to all members
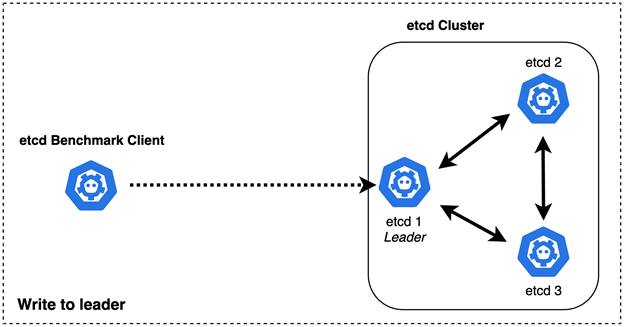
Figure 1. etcd benchmarking topology (Write to leader)
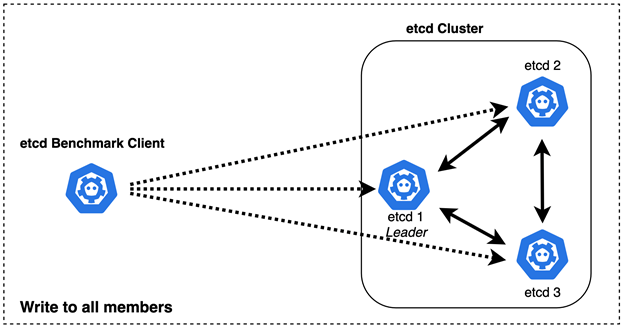
Figure 2. etcd benchmarking topology (Write to all members)
etcd uses the Raft consensus algorithm to replicate requests among members and reach agreement. Raft is leader-based; the leader handles all client requests which need cluster consensus. However, the client does not need to know which node is the leader. Any request that requires consensus sent to a follower is automatically forwarded to the leader. Requests that do not require consensus (for example, serialized reads) can be processed by any cluster member.
The basic put logic uses the following. When the client initiates a write request, if the leader receives the write request, it will write the request to the local WAL (Write-Ahead Log) and broadcast the request to each node. If more than half of the nodes have successfully written the local WAL and respond to the leader, the log entry corresponding to the request is marked as submitted. Then the leader will send response to the client; if the follower receives the write request, it will forward the request to the leader and the remaining logic is similar to the above case.
The setup has four EC2 clusters with the following configurations, and uses “cluster” placement group for those instances to reduce network latency. The benchmark client used a single m6g.4xlarge instance.
|
Comparison group |
Cluster/Processor |
Service type |
EC2 type |
Storage (Size) |
Instance count |
|
1
|
Cluster 1: Graviton2 |
etcd |
m6g.xlarge |
EBS gp3 (50G) |
3 |
|
Cluster 2: Xeon |
etcd |
m5.xlarge |
EBS gp3 (50G) |
3 |
|
|
2 |
Cluster 3: Graviton2 |
etcd |
m6g.2xlarge |
EBS gp3 (50G) |
3 |
|
Cluster 4: Xeon |
etcd |
m5.2xlarge |
EBS gp3 (50G) |
3 |
Table 1. Test cluster configurations
The benchmark tests were performed with the following software versions and test parameters.
|
Component name |
Version |
|
etcd |
V3.5 |
|
go |
1.16.3 |
|
Kernel |
5.10.50-44.132.amzn2.x86_64 5.10.50-44.132.amzn2.aarch64 |
|
Operating System |
Amazon Linux 2 |
|
Test config parameter |
Value |
|
Number of keys |
100,000 |
|
Key size in bytes |
8 |
|
Value size in bytes |
256 |
|
Number of connections |
100 |
|
Number of clients |
1000 |
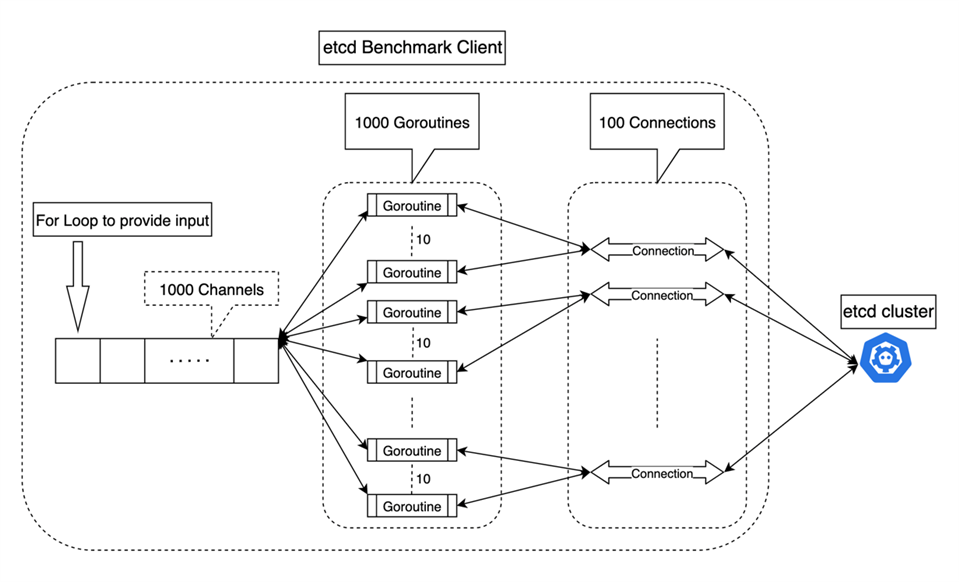
Figure 3. etcd benchmark architecture
Figure 3 illustrates the internal logic of benchmark program.Each test run will create 1000 client goroutines (corresponding to the configured client parameters) which send the request through the configured 100 keep-alive HTTP2 connections (10 goroutines share one connection). That adds up to 100k requests sent from benchmark on each run. The result shown in the following tables are an aggregated result of 20 consecutive test run iterations after 20 test run iterations as warmup phase, reporting average throughput and average latency. We observe 18% performance uplift by running open-source etcd on Graviton2-based instances compared to running on Xeon-based instances.
“Write to leader” case:
|
Instance size |
M5 (Requests/sec) |
M6g (Requests/sec) |
Performance gain (%) |
|
xlarge |
37924.91 |
42485.98 |
12% |
|
2xlarge |
55225.25 |
64932.72 |
18% |
Table 2. etcd throughput performance results (Write to leader) on M5 vs. M6g
|
Instance size |
M5 (ms latency) |
M6g (ms latency) |
Performance gain (%) |
|
xlarge |
26.20 |
23.40 |
12% |
|
2xlarge |
18.00 |
15.29 |
18% |
Table 3. etcd latency performance results (Write to leader) on M5 vs. M6g
“Write to all members” case:
|
Instance size |
M5 (Requests/sec) |
M6g (Requests/sec) |
Performance gain (%) |
|
xlarge |
55262.25 |
60674.89 |
10% |
|
2xlarge |
74817.70 |
80485.83 |
8% |
Table 4. etcd throughput performance results (write to all members) on M5 vs M6g
|
Instance size |
M5 (ms latency) |
M6g (ms latency) |
Performance gain (%) |
|
xlarge |
17.97 |
16.34 |
10% |
|
2xlarge |
13.24 |
12.30 |
8% |
Table 5. etcd throughput performance results (Write to all members) on M5 vs M6g
The following figures show the throughput and latency comparison between M5 and M6g instances running etcd (Write to leader case).
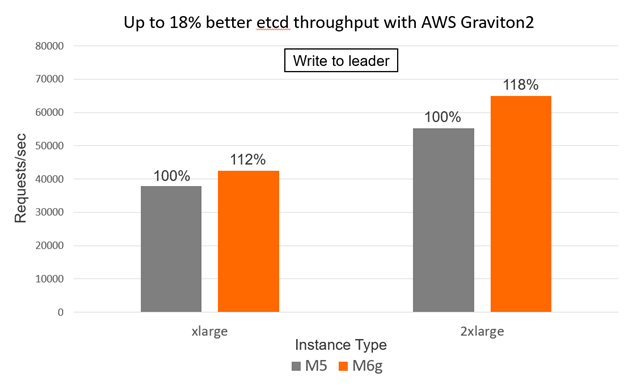
Figure 4. Performance gains for M6g vs. M5 instances for Write to leader case
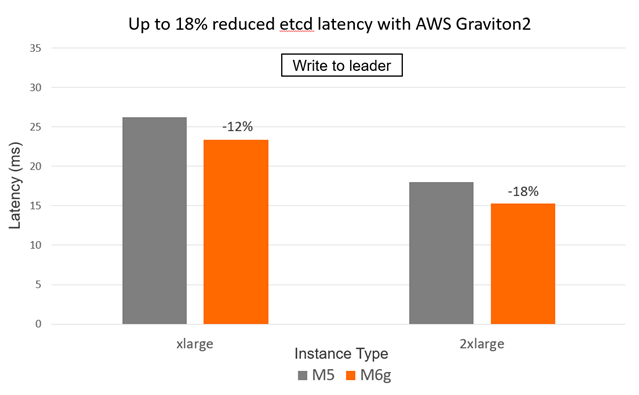
Figure 5. Lower latency for M6g vs. M5 instances for Write to leader case
The following figures show the throughput and latency comparison between M5 and M6g instances running etcd (Write to all members case).
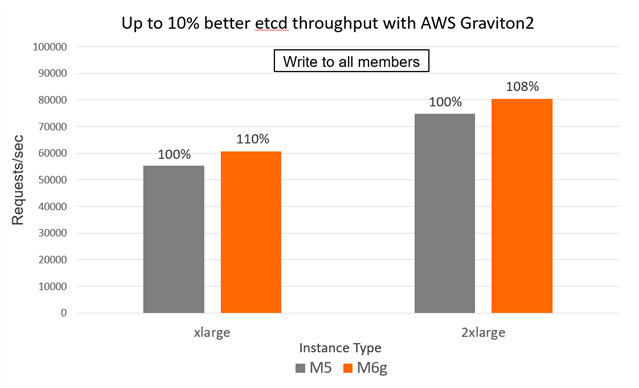
Figure 6. Performance gain for M6g vs. M5 instances for Write to all members case
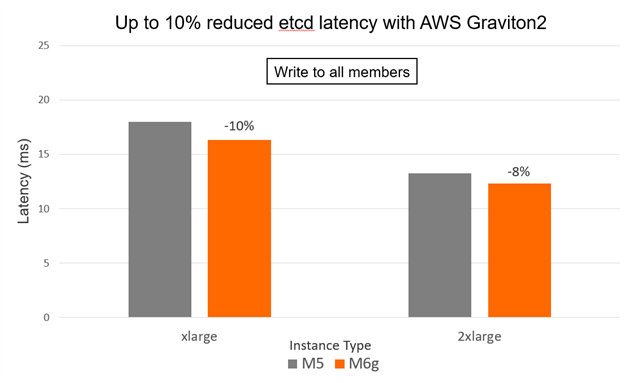
Figure 7. Lower latency for M6g vs. M5 instances for Write to all members case
Conclusion
To conclude, etcd deployed on AWS Graviton2 provides the following benefits over equivalent 5th generation x86 based EC2 instances. Up to 18% more throughput, 18% reduced latency in addition to being priced 20% less.
Deploying applications on these instances is simple and efficient without extra overhead for major complexities. For details on how to migrate existing applications to AWS Graviton2, please check this github page.
Visit the AWS Graviton page for customer stories on adoption of Arm-based processors. For any queries related to your software workloads running on Arm Neoverse platforms, feel free to reach out to us at sw-ecosystem@arm.com.

By Ker Liu
Re-use is only permitted for informational and non-commercial or personal use only.
