What's new in Arm Performance Libraries 26.01
Arm Performance Libraries (ArmPL) 26.01 is now available for Linux, macOS and Windows. It can be used to accelerate a wide variety of use cases, including engineering, scientific and machine learning cases.
By Nick Dingle

ArmPL provides optimized standard core math libraries for numerical applications on 64-bit Arm (AArch64) processors. It includes optimized implementations of sparse and dense linear algebra functions including BLAS and LAPACK, Fast Fourier Transforms (FFTs), and random number generation (RNG) functions. These are built with OpenMP parallelism to maximize performance in multi-processor environments. In addition, it also includes high performing scalar and vector math.h routines through the libamath library.
ArmPL 26.01 features new sparse triangular solve functionality, more RNG distributions, reproducible math options in libamath, and performance gains across BLAS, LAPACK, and sparse routines. For a full list of changes, including details of support for LAPACK 3.12.1, see the full release note.
To get started with Arm Performance Libraries 26.01, install it using a package manager or download the appropriate installer.
Matrix-matrix multiplication performance improvements
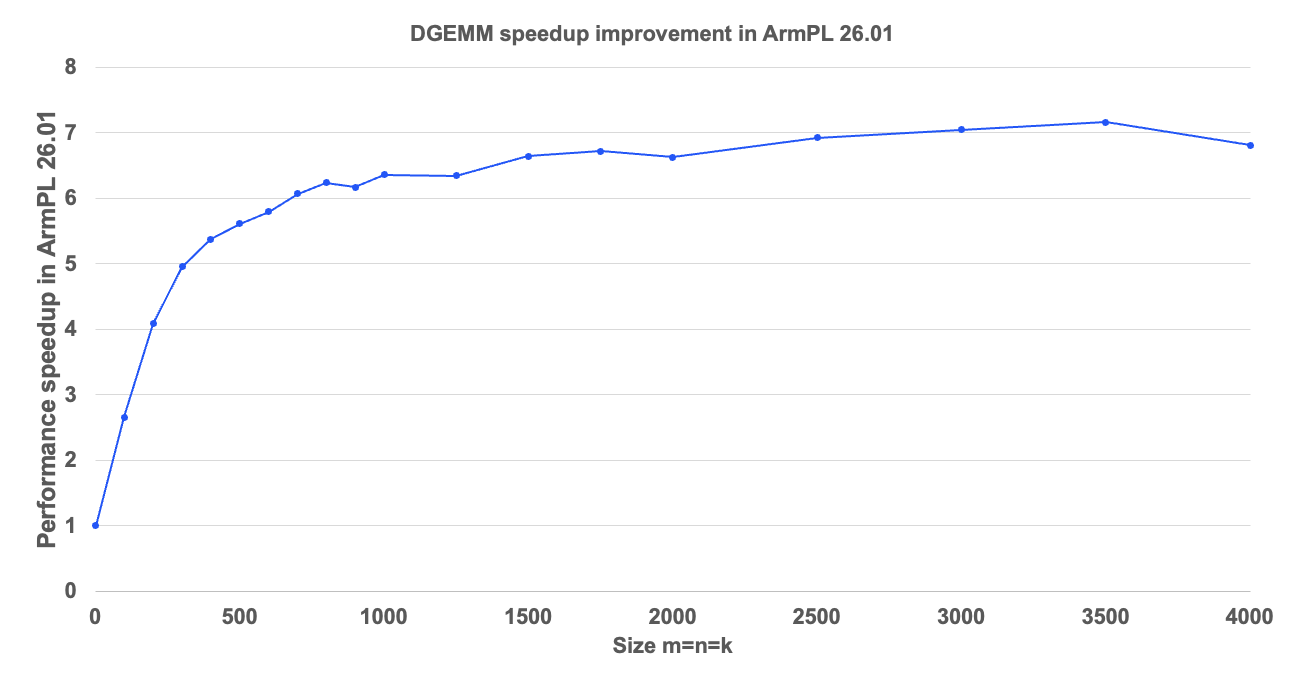
We have improved single and double-precision real matrix-matrix multiplication (e.g. BLAS SGEMM and DGEMM calls) by using SME instead of Neon on compatible M-series Apple silicon running macOS. The graph below compares ArmPL 26.01's DGEMM performance with that of ArmPL 25.07 across a range of square input matrix sizes. It demonstrates speedups of up to 7x.
Sparse triangular solve for supernodal matrices
ArmPL 26.01 adds support for solving sparse triangular systems using the supernodal matrix format with the new fully-parallelized armpl_spsv_exec_* functions. We also provide new C functions for creating supernodal matrices (armpl_spmat_create_supernodal_*). You can find a description of the supernodal format and full documentation of the new routines in the online reference guide. See the example programs distributed with ArmPL 26.01 to learn more about using these functions with both upper and lower triangular input matrices.
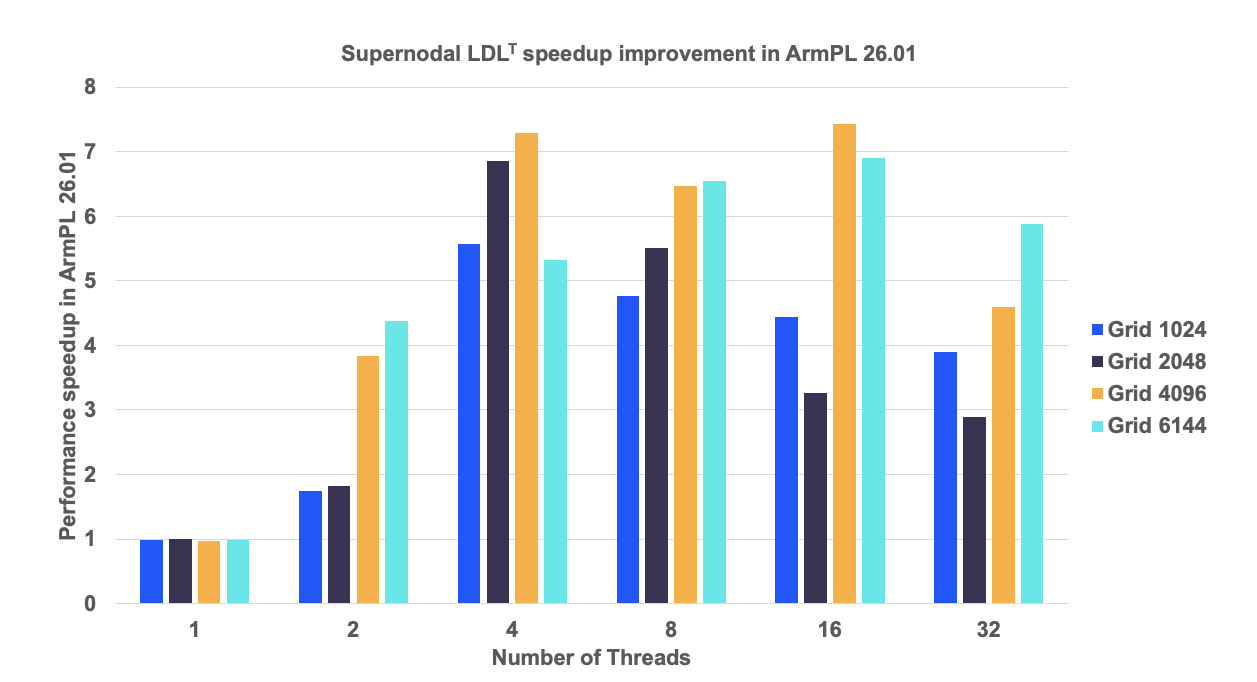
The graph shows the performance speedup of armpl_spsv_exec_d in ArmPL 26.01 relative to 25.07 for four problem sizes and multiple thread counts. Each problem is a square system solved as part of an LDLᵀ factorization, with matrix dimension n=Grid-squared (e.g., Grid 1024 corresponds to n=10242).
The matrices exhibit a supernodal structure. In ArmPL 26.01, the runs initialize the sparse matrix using the new supernodal interface, armpl_spmat_create_supernodal_d, instead of constructing a CSC matrix via armpl_spmat_create_csc_d as in ArmPL 25.07. Using the supernodal format enables a more scalable multithreaded triangular-solve implementation, delivering up to 7x higher performance. This new supernodal sparse matrix format is being adopted to accelerate large sparse linear-system solves in Panua-Pardiso on Arm systems.
New random number generation functionality
ArmPL 26.01 adds functionality to generate integer variates according to the Multinomial distribution (viRngMultinomial), and to generate single- and double-precision random numbers according to the Gamma distribution (vsRngGamma and vdRngGamma respectively). ArmPL 26.01 also adds support for the POISNORM algorithm to the Poisson distribution routine viRngPoisson. This calculates Poisson distributions using either the inversion method or from normally-distributed values. The source code for these new additions is publicly available in OpenRNG 26.01 on Arm's Gitlab.
Reproducible libamath
ArmPL 26.01 includes a new reproducible Linux-only variant of libamath that can act as a partial drop-in replacement for the default 3.5 ULP library. It guarantees identical results between scalar and vector (Neon and SVE) calls for supported functions and is intended for applications that require deterministic numerical behavior across different vectorization paths. Not all libamath functions are available in reproducible form and GNU ABI symbols are not provided. Full details are provided in the online reference guide.
Conclusion
The latest release of Arm Performance Libraries 26.01 is out now. Let us know in the forum if you have any questions or comments.

By Nick Dingle
Re-use is only permitted for informational and non-commercial or personal use only.
