What is new in LLVM12 for Arm
This blog provides more details about LLVM 12 for Arm and the new features that it provides.
By Ashok Bhat

LLVM 12 is now available with improved support for Arm. It provides a native Windows on Arm toolchain, adds support for new Arm cores, debugging support for SVE/2 applications and performance improvements to a key CPU benchmark.
Windows-on-Arm native 64-bit Arm toolchain
LLVM 12 release provides native 64-bit Arm Windows on Arm LLVM binaries, thanks to Linaro’s effort (see this blog for more detail). LLVM now has 64-bit Arm Windows on Arm buildbots, hosted by Linaro. Further improvements are planned for the upcoming LLVM releases including better debug support.
New processor support
LLVM 12 adds mcpu support for Arm Neoverse cores, Neoverse V1 and Neoverse N2, Arm Cortex-A78C, Arm Cortex-R82 and Fujitsu A64FX. When provided with the relevant CPU flag, the compiler automatically picks the right architecture features and tunes for the target processor.
The following table describes the flag for each target processor:
|
Processor |
Flag |
|
Arm Neoverse V1 |
-mcpu=neoverse-v1 |
|
Arm Neoverse N2 |
-mcpu=neoverse-n2 |
|
Arm Cortex-A78C |
-mcpu=cortex-a78c |
|
Arm Cortex-R82 |
-mcpu=cortex-r82 |
|
Fujitsu A64FX |
-mcpu=a64fx |
Out-of-line Atomics for LSE deployment
AArch64 Large System Extensions (LSE) were introduced in Armv8.1-A. These provide more efficient atomic instructions for large multi-core systems.
LLVM 12 adds support for a new flag ‘-moutline-atomics', which detects at runtime whether the processor supports LSE. It then uses these new atomic instructions if possible, falling back to Armv8.0-A LL/SC loops on processors without LSE support. This option behaviour mirrors similar support available within GNU family of projects. We are working towards making this option enabled by default in the upcoming LLVM13 release.
Better SVE/SVE2 intrinsics support
LLVM11 was the first LLVM release to add vector-length agnostic SVE intrinsics (also known as ACLE) support. LLVM 12 adds vector-length specific ACLE support and improves vector-length-agnostic support.
SVE code-generation infrastructure
Enabling SVE auto-vectorization in LLVM has been a long journey and we have significant progress in LLVM12. For the first time, LLVM is now able to vectorize certain loops using width-agnostic SVE auto-vectorization. For example, consider the following loop, which is adapted from the TSVC_2 set of loops:
void s000(double * __restrict a, double * __restrict b) {
unsigned LEN_1D = 1024;
#pragma clang loop vectorize_width(2, scalable) interleave(disable) unroll(disable)
for (int i = 0; i < LEN_1D; i++) {
a[i] = b[i] + 1;
}
}
The key to enabling SVE autovectorization is #pragma clang loop vectorize_width(2, scalable). This tells LLVM to attempt to vectorize the loop using a scalable vectorization width of 2 lanes. With this support, we are now able to work towards the eventual goal of enabling SVE auto-vectorization by default in LLVM.
Further information on this functionality can be found in our recent Linaro Virtual Connect talk on SVE in LLVM.
SPEC CPU 2017 CPU benchmark improvements
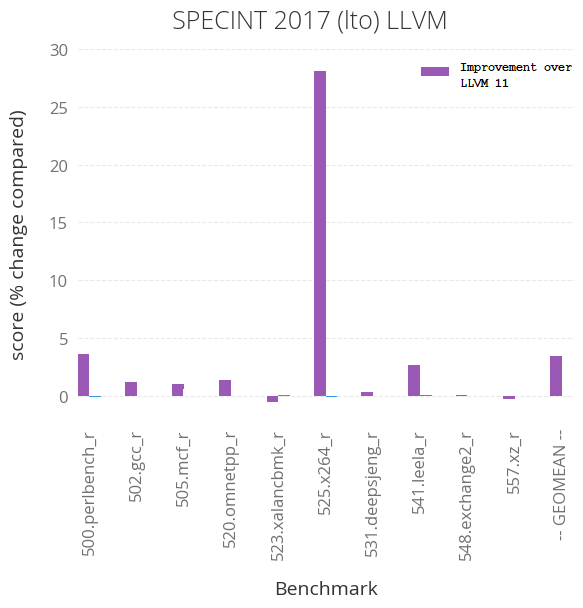
LLVM 12 has added new generic vectorization related optimizations that improves SPEC CPU 2017 Integer 525.x264_r benchmark. On Arm Neoverse N1 hardware, we see an uplift of 25 percent for this individual benchmark and an overall 2 percent improvement in SPEC CPU 2017 INT score. LLVM now identifies SAD pattern and combines UDADDV instructions to generate vector add. LLVM also supports epilogue vectorization. The chart below shows the various benchmark improvements over LLVM 11.
Improvements to MVE
MVE is an extension of the Armv8.1-M architecture. It is designed to give a significant performance uplift for machine learning and digital signal processing workloads on CPUs for embedded devices, such as Arm Cortex-M55.
LLVM 12 brings improvements to vectorization and code quality for MVE, leading to significant improvements to both performance and code size for a range of workloads. A particular highlight is the ability to fully utilise the capabilities of MVE to allow tail-predicated vectorization of reduction loops.
SVE/2 support in LLDB
LLDB now has full support for debugging SVE/2 applications including dynamic size update of SVE registers. Work is progressing on supporting Pointer Authentication (PAuth), Memory Tagging Extension (MTE) and Top Byte Ignore (TBI) architecture features in LLDB that are expected to be part of LLVM13 release.
Looking forward
LLVM 12 has major improvements for Arm-based hardware including support for newer CPUs, Windows on Arm native binaries and more. We (Arm and our partners) are working on more features for the forthcoming LLVM 13 (expected in Sep/Oct 2021) where you can look forward to exciting new features and performance improvements.

By Ashok Bhat
Re-use is only permitted for informational and non-commercial or personal use only.
