What is new in LLVM 20?
Discover what's new in LLVM 20, including Armv9.6-A support, SVE2.1 features, and key performance and code generation improvements.

LLVM 20.1.0 was released on March 11th, 2025. Arm teams focused on integrating support making sure LLVM has the latest Arm architecture support as well as gets best performance out of it. Below is the summary of key contributions to LLVM 20.
To find out more about the previous LLVM release, read What is new in LLVM 19?
New architecture and CPU support
Armv9.6-A architecture support
By Maciej Gabka
LLVM 20 implements full assembly support and relevant command line options for the Armv9.6-A architecture. Learn more about the new extensions in the annual announcement blog post. The new architecture extensions implemented in LLVM are documented also on the Armv9.6-A architecture extension page. Moreover, LLVM 20 assembler is compatible with the December 2024 release of the architecture XML published as part of the Exploration Tools, the announced changes to architecture are documented in the release notes. If you are interested in the full instruction set, see the December 2024 release of Arm A-profile A64 Instruction Set Architecture.
Scalable Vector Extension 2.1 (SVE2.1) ACLE support
By Maciej Gabka
LLVM 20 includes support for the beta version of the SVE2.1 and Scalable Matrix Extension 2.1 (SME2.1) ACLE which are now available in the ACLE Q4 2024 specification release.
It enables LLVM users to generate instructions for those architecture features directly from C and C++ code.
SME ACLE ZA-agnostic support
By Sander De Smalen
To avoid the cost of setting up the lazy save scheme around calls to functions that don't use SME ZA state, the __arm_agnostic keyword attribute was defined in the Q4 2024 ACLE. This enables the user to specify that the function will preserve all SME ZA state if it exists. In practice this means such functions can be called from any function regardless of their ZA state without incurring the cost of a lazy-save. More details can be found in the clang attributes documentation.
Example:
// `my_compatible_fn` can be called in any context using the `__arm_agnostic`
// and `__arm_streaming_compatible` attributes.
void my_compatible_fn(void)
__arm_streaming_compatible
__arm_agnostic("sme_za_state");
void init_sme(void) __arm_streaming __arm_out("za", "zt0");
void use_sme(void) __arm_streaming __arm_inout("za", "zt0");
__arm_new("za", "zt0")
__attribute__((target("armv9-a+sme")))
void some_sme_function(void) __arm_streaming {
init_sme();
my_compatible_fn(); // no lazy-save is required
use_sme();
}
__attribute__((target("armv8-a")))
void some_non_sme_function(void) {
my_compatible_fn(); // The caller doesn't require +sme to call a __arm_agnostic("sme_za_state")
// or __arm_streaming_compatible function.
}Performance improvements
Spec 2017 performance improvements
By Kiran Chandramohan
A set of LLVM transformations developed by our team has delivered significant performance improvements across multiple SPEC2017 benchmarks.
Canonicalizing getelementptr (GEP) instructions with constant base pointers and offsets improved performance by over 3% in the 548.exchange2_r benchmark by enabling better constant folding and shared offset computation. Enhancements to the Superword Level Parallelism (SLP) vectorizer, particularly in load instruction ordering and clustering, yielded a 3% improvement in 525.x264_r.
Loop-Invariant Code Motion (LICM) was improved by teaching Clang to emit nuw (no unsigned wrap) GEPs and enhancing BasicAA to leverage them for alias analysis, enabling better hoisting/sinking of struct field updates and delivering a 0.89% gain in 557.xz_r. Function specialization for constants passed by reference, commonly seen in Flang code, significantly boosted performance in the 503.bwaves_r benchmark. Additionally, the AArch64 backend was optimized to avoid generating expensive ld4 instructions for uitofp(ld4) patterns, preferring more efficient and/shift operations, resulting in a 22% gain in 538.imagick_r.
Overall, these and other community-driven improvements led to a 3% uplift in SPEC2017 floating-point rate (fprate) and a 1% gain in integer rate (intrate) on Graviton 4.
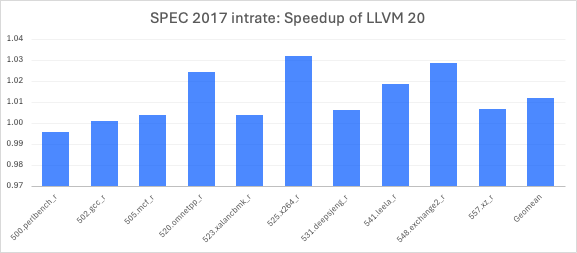
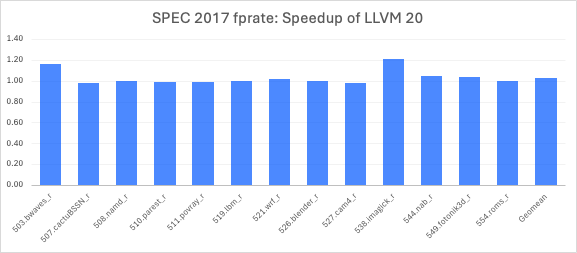
Our team also improved the scheduling model for fdiv and square root instructions. These improvements provided a 2.5% improvement for 519.lbm_r.
Code generation improvements
Function multiversioning improvements
By Alexandros Lamprineas
Function multiversioning (FMV) support has been added in LLVM 16, in this release the following improvements were made based on the feedback from users:
- We have removed FMV features without compiler support and consolidated others following the ACLE specification.
- We now generate FMV feature dependencies using TableGen.
- We have added runtime detection for depend-on FMV features.
- We have introduced new metadata info for multi-versioned functions.
- We have added support in GlobalOpt for optimizing calls that can be statically resolved, without routing them through an ifunc resolver function.
Better SVE code generation for add reduction loops
By Samuel Tebbs
LLVM can now generate different variants of NEON dot product instructions (udot, sdot and usdot). For example, the following code sample:
#include <stdint.h>
uint32_t udot(uint8_t *a, uint8_t *b, unsigned N) {
uint32_t total = 0;
for (unsigned i = 0; i < N; i++) {
total += a[i] * b[i];
}
return total;
}
int32_t sdot(int8_t *a, int8_t *b, unsigned N) {
int32_t total = 0;
for (unsigned i = 0; i < N; i++) {
total += a[i] * b[i];
}
return total;
}
int32_t usdot(uint8_t *a, int8_t *b, unsigned N) {
int32_t total = 0;
for (unsigned i = 0; i < N; i++) {
total += a[i] * b[i];
}
return total;
}compiled with-O3 -march=armv8-a+dotprod+i8mmflags to:
udot: // @udot
[...]
.LBB0_11: // %vector.body
ldr q1, [x13], #16
ldr q2, [x12], #16
subs x8, x8, #16
udot v0.4s, v2.16b, v1.16b
[...]
sdot: // @sdot
[...]
.LBB1_11: // %vector.body
ldr q1, [x13], #16
ldr q2, [x12], #16
subs x8, x8, #16
sdot v0.4s, v2.16b, v1.16b
[...]
usdot: // @usdot
[...]
.LBB2_11: // %vector.body
ldr q1, [x13], #16
ldr q2, [x12], #16
subs x8, x8, #16
usdot v0.4s, v1.16b, v2.16b
[...]SVE dot products require the addition of-mllvm -vectorizer-maximize-bandwidthto the compile command and further tweaks to the cost model are required for SVE dot products to be produced in all cases:
clang -O3 -march=armv8-a+sve+i8mm -mllvm -vectorizer-maximize-bandwidth=1 -mllvm -force-target-instruction-cost=1 |
There is an ongoing effort in the LLVM community to go further and reduce the need to use extra flags.
Support for SVE2 complex dot-product vectorization
By Nicholas Guy
Using some of the functionality added to LLVM to enable generation of the dot product instructions, the complex deinterleaving pass (introduced in LLVM 16) was extended to support complex dot product instructions found in the SVE2 instruction set.
Current support only extends to cdot operations where the rotation would be either 90° or 180°. Support for 0° and 270° (and thus full complex dot product) operations will be implemented in a future LLVM release.
The following C++ snippet performs a partial complex dot product, with a rotation of 180°:
#include<stdint.h>
struct cint16_t {
int8_t real;
int8_t imag;
};
int32_t cdot(cint16_t *a, cint16_t *b, uint32_t N) {
int32_t res = 0;
#pragma clang loop vectorize_width(16, scalable) unroll(disable)
for(uint32_t i = 0; i < N; i++)
res += (a[i].real * b[i].real) + (a[i].imag * b[i].imag);
return res;
}when compiled with -O2 -march=armv9-a, compiler will generate the following assembly for the loop body:
.LBB0_5: // %vector.body
// =>This Inner Loop Header: Depth=1
add x12, x0, x8
ld1b { z2.b }, p0/z, [x0, x8]
ld1b { z4.b }, p0/z, [x1, x8]
addvl x11, x11, #-1
ldr z3, [x12, #1, mul vl]
add x12, x1, x8
addvl x8, x8, #2
ldr z5, [x12, #1, mul vl]
cdot z0.s, z2.b, z4.b, #180
cdot z1.s, z3.b, z5.b, #180
cbnz x11, .LBB0_5
// %bb.6: // %middle.block
add z0.s, z0.s, z1.s
ptrue p0.s
uaddv d0, p0, z0.s
fmov w8, s0
cmp x10, x9
b.eq .LBB0_9Base loop vectorization support for SVE2 histcnt instruction
By Graham Hunter
LLVM is now able to vectorize some loops containing histogram-like operations using the histcnt instruction from SVE2.
Given a loop like the following (with the restrict so that the compiler knows the buckets don't alias with the indices):
void simple_histogram(int *restrict buckets, unsigned *indices, int N, int inc) {
for (int i = 0; i < N; ++i)
buckets[indices[i]] += inc;
}If we compile that using the following optimization flags: -O3 -march=armv9-a -mllvm -force-vector-interleave=1 -mllvm -enable-histogram-loop-vectorization then we get a loop using histcnt:
.LBB0_4: // %vector.body
// =>This Inner Loop Header: Depth=1
ld1w { z1.s }, p0/z, [x1, x10, lsl #2]
incw x10
ld1w { z2.s }, p0/z, [x0, z1.s, uxtw #2]
histcnt z3.s, p0/z, z1.s, z1.s
mla z2.s, p0/m, z3.s, z0.s
st1w { z2.s }, p0, [x0, z1.s, uxtw #2]
cmp x9, x10
b.ne .LBB0_4We hope to enable this transformation by default in a later LLVM release, once the cost model is tested.
Tools improvements
Flang
By Kiran Chandramohan
Recent updates to Flang include expanded driver support for flags such as -B, config file options, loop unrolling (-f[no-]unroll-loops), OpenMP disabling (-fno-openmp), zero-initialization of global variables, and automatic ArmPL linkage with -fveclib=ArmPL. New intrinsics have been added, including GETUID, GETGID, MALLOC, FREE (for Cray pointers), a functional form of the SYSTEM intrinsic, and the non-standard LNBLNK.
Parser and semantics support was introduced for various OpenMP constructs such as scope, dispatch, error directives, map and declare mapper, atomic compare, and clauses including master, align, fail, grainsize, and num_tasks. These currently generate TODO messages during lowering. On the lowering and code generation front, support was added for pointers and allocatables in the copying clause, along with improvements to privatization and reduction handling. Several bug fixes were also made to strengthen OpenMP support in Flang.
In Fortran, marking a derived type with the VALUE attribute in a BIND(C) interface specifies that the argument or return value should be passed by value, akin to a C struct. Flang’s target-specific code has been updated to support both passing and returning such values in compliance with the AArch64 ABI, ensuring correct behavior and adherence to platform calling conventions.
Try LLVM 20 version from the upstream LLVM project https://github.com/llvm/llvm-project.
Arm Toolchain project https://github.com/arm/arm-toolchain toolchains for Embedded and Linux use cases.

Re-use is only permitted for informational and non-commercial or personal use only.
