Persistency for Synchronization-Free Regions
Emerging non-volatile memories (NVM), such as 3D XP and STT-MRAM, offer the promises of combining the performance and byte-addressability of DRAM with the density and non-volatility of NAND. Such non-volatile memories can be revolutionary for computer systems.
By William Wang

Emerging non-volatile memories (NVM), such as 3D XP and STT-MRAM, offer the promises of combining the performance and byte-addressability of DRAM with the density and non-volatility of NAND. Such non-volatile memories can be revolutionary for computer systems. NVM can be used to sit between DRAM and SSD as a fast storage tier, displace DRAM as main memory for cost reduction or transformative capacity, or completely remove the storage tier by acting as both memory and storage (Figure 1). At Arm Research, we’re particularly interested in the NVM as persistent memory use case, where memory and storage are merged as one tier and no more data copying is needed between storage and memory, such use case poses interesting challenges that are worth addressing, such as ensuring always correct recovery of systems following power or system failures.
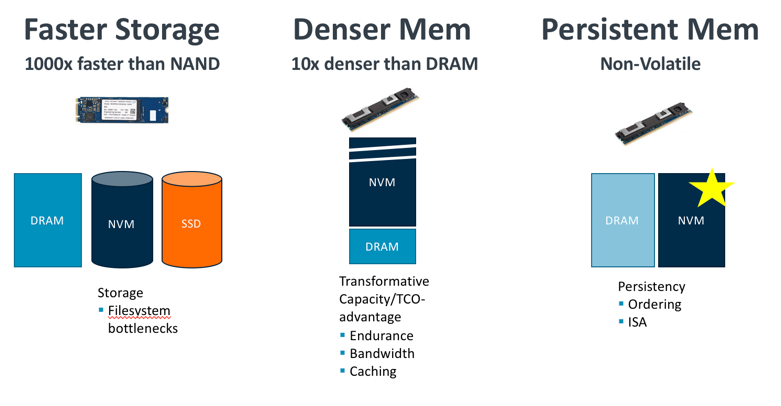 Figure 1. Multiple system use-cases for emerging non-volatile memories.
Figure 1. Multiple system use-cases for emerging non-volatile memories.
For systems with non-volatile main memories, i.e., NVDIMM, failure atomicity guarantees systems can always recover to a consistent state following a power or system failure. Such failure atomicity can be achieved with journaling and flushing as with filesystems for storage. Similarly, with non-volatile main memories, failure atomicity can be achieved with user applications using logging, flushing, and barriers that order such operations. Logging, either undo or redo logging, ensures atomicity when a failure interrupts the last atomic operation from completion. Cache flushing ensures volatile caches do not hold persistent data from reaching the point of persistence, so persistent data won’t be lost when a sudden failure occurs. Barriers help prevent potential reordering in the memory hierarchy, as caches and memory controllers may reorder memory operations. For example, a barrier ensures the undo log copy of the data gets persisted onto the persistent memory before the data is mutated in-place, so it’s guaranteed that the last atomic operation can be rewound, should a failure occur. However, it’s non-trivial to add such failure atomicity in user applications with low-level operations such as write logging, cache flushing, and barriers [1].

The paper was presented at PLDI’18 in Philadelphia
Programming Challenges with Persistent Memory
Arm Research worked with University of Michigan on addressing the programming challenges with persistent memory, i.e., simplifying persistent programming for porting legacy applications to persistent memory while limiting the performance degradation. The work resulted in a joint paper titled “Persistency for Synchronization-Free Regions” that was presented at PLDI’18 in Philadelphia. The paper reduces developer efforts for porting legacy applications to persistent memory to recompilations only. No code rewrite is needed for multithreaded code written in C++ with lock primitives, as compilers can be instrumented to take care of failure atomicity by detecting critical sections (or synchronization-free regions) and instrumenting with undo logging. However, the convenience of failure-atomic synchronization-free regions (SFR) does not come for free, due to additional compiler passes and instrumentation code emitted in such compiler passes. The paper proposes a decoupled-SFR approach that decouples logging from each worker thread by creating a background thread that takes care of logging only with each worker thread. The decoupled-SFR performs 65% better than state-of-the-art ATLAS design as evaluated with workloads such as TPCC and TATP (Exhibit 1).
SFR compared to other state-of-the-art lock-based persistent programming models
ATLAS [2] |
NV-Threads[3] |
SFR[4] |
|
|
From |
HP |
HP |
UoM & Arm |
|
Multithread Support |
Yes |
Yes |
Yes |
|
Developer Effort |
No rewrite. Compiler infers from locks |
No rewrite. Compiler infers from locks |
No rewrite. Compiler infers from C++ sync primitives |
|
Granularity |
Coarse (outermost CS) |
Coarse (4 KB pages) |
Fine (sync free regions as delimited by sync-ops) |
|
Performance Overhead |
<1% to 4x vs DRAM – cache flushing |
>2x faster than ATLAS |
65% better than ATLAS |
Find out more
Use the links below to download the full paper, 'Persistency for Synchronization-Free Regions', to watch the talk, or to see the talk slides from PLDI.
Read the full paper Watch the talk Download the talk slides
References
- Marathe, V.J., Seltzer, M., Byan, S. and Harris, T., 2017, July. Persistent memcached: bringing legacy code to byte-addressable persistent memory. In 9th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 17).
- Chakrabarti, D.R., Boehm, H.J. and Bhandari, K., 2014. Atlas: Leveraging locks for non-volatile memory consistency. ACM SIGPLAN Notices, 49(10), pp.433-452.
- Hsu, T.C.H., Brügner, H., Roy, I., Keeton, K. and Eugster, P., 2017, April. Nvthreads: Practical persistence for multi-threaded applications. In Proceedings of the Twelfth European Conference on Computer Systems (pp. 468-482). ACM.
- Gogte, V., Diestelhorst, S., Wang, W., Narayanasamy, S., Chen, P.M. and Wenisch, T.F., 2018, June. Persistency for synchronization-free regions. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation (pp. 46-61). ACM.

By William Wang
Re-use is only permitted for informational and non-commercial or personal use only.
