A practical guide to LLM quantization on Arm Mobile CPUs
Explore quantization techniques for mobile AI, compare INT8 and INT4 approaches, and see Gemma benchmark results on Arm CPUs

Introduction:
To help mobile developers run LLMs on devices, we use quantization to compress models. This blog builds on a previous quantization blog and gives a practical overview of various quantization techniques. We focus on the key challenges specific to LLMs and the techniques used to address them. We also present benchmark results for Gemma-3 and Gemma-4-E2B models on SME2-enabled devices. These benchmarks show the real-world performance of LLMs running on CPUs on mobile hardware. By the end of this blog, you will understand why quantization is important for mobile AI. You will understand the trade-offs between different quantization techniques, and the performance achievable on SME2-enabled devices using LiteRT-LM and KleidiAI.
Why quantize?
Running billions of parameters on a mobile device
The devices in our pockets are becoming more intelligent as LLMs are becoming part of everyday life. We can now point our phones at our surroundings to interpret them, answer questions, and assist with complex tasks. However, these interactions still rely on large-scale cloud infrastructure. This requires data to leave the device, raising concerns around user privacy, operational cost, and increased latency.
This raises a key question: what if these models could run directly on-device and avoid this round trip to the cloud? To achieve this, we must execute these models within strict memory, compute, and power constraints. This is where quantization becomes essential. LLMs have grown rapidly in both scale and diversity, including models designed for on-device use such as Gemma-3-1B, Qwen-3.5-2B, and Llama-3 3B, where “B” represents billions of parameters.
Figure 1 illustrates the evolution of model size over the years. These models rely on billions of parameters, where weights interact with data-dependent activations computed at runtime. These values are typically represented using high-precision floating-point numbers. This increases memory and compute requirements, making deployments on mobile devices challenging.
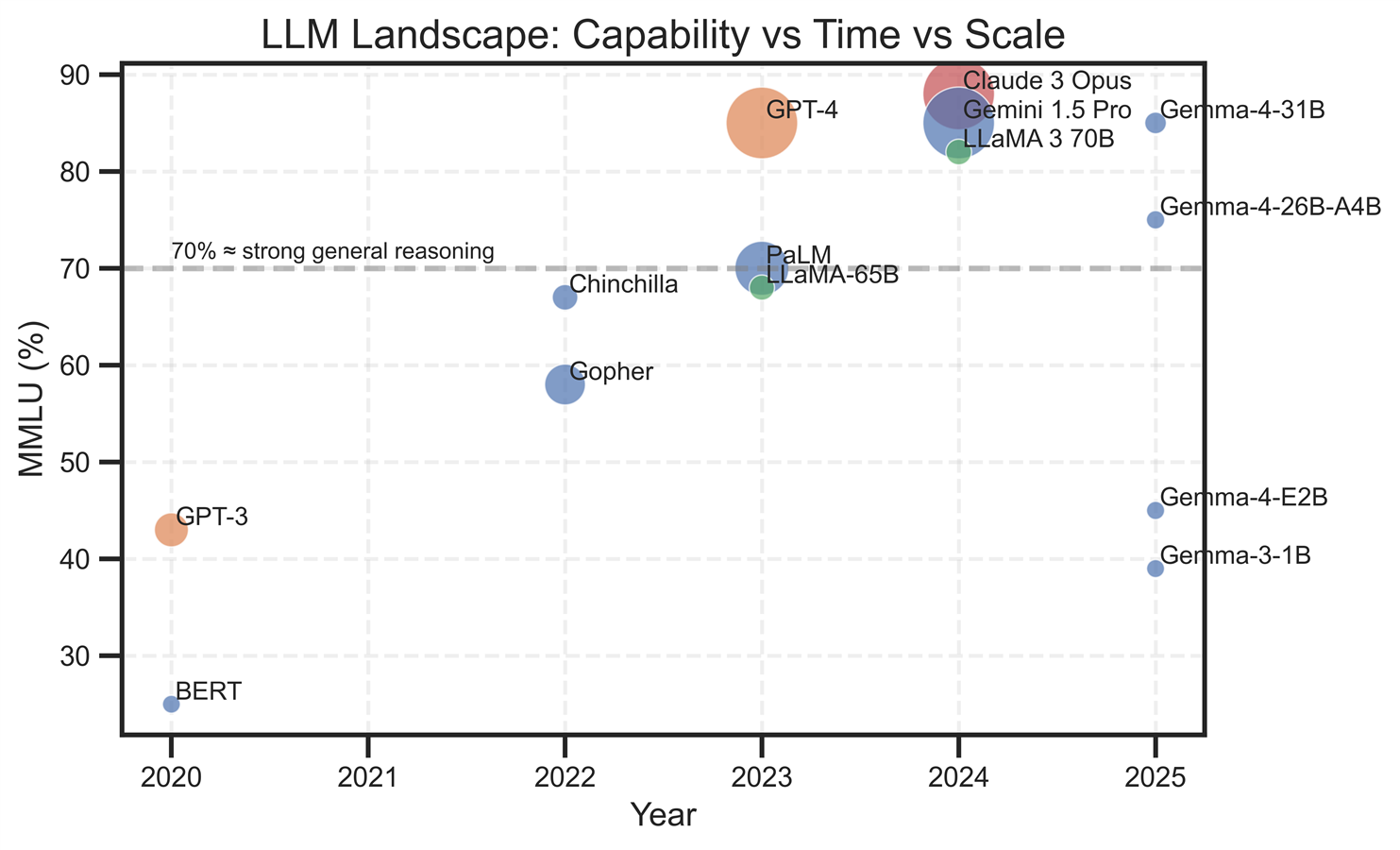
Figure 1: Show the accuracy of different models against the Massive Multi-Task Language Understanding dataset. The size of each data point indicates the number of parameters in the model (larger data point means more parameters).
Models are trained using high-precision data (FP32) to maximize accuracy. The downside is that the model requires a large amount of memory. Quantization reduces numerical precision to a smaller set of discrete values, trading a small amount of accuracy for gains in efficiency and reduced model size. For example, reducing precision from FP32 to 4-bit can shrink a model by up to 8×, turning a 10 GB model into 1.25 GB. Actual size reductions can be lower because of quantization overheads such as scales and metadata. This makes it more practical to run LLMs on resource-constrained devices. It can also improve performance by reducing memory bandwidth and compute requirements, while also enabling more efficient vectorization that increases parallel throughput.
In a previous blog, we discussed Post Training Quantization (PTQ) and Quantization Aware Training (QAT). For mobile developers, PTQ techniques dominate in practice because they enable large pre-trained models to run within the strict latency, memory, and power constraints of mobile devices. PTQ only requires calibration datasets, whereas techniques such as QAT require large-scale model updates and high-quality training data.
Why quantizing is hard for LLMs
Quantizing an LLM is challenging for three core reasons:
- Numerical Sensitivity: Small precision errors can propagate and amplify across layers, particularly in sensitive components such as attention mechanisms. These errors can disrupt emergent behaviors such as reasoning.
- Distribution and Scaling: Unpredictable activations, outliers, and differences between layers make consistent quantization difficult which can lead to significant loss of information.
- System-Level Constraints: Large model sizes create deployment challenges. Careful calibration is often required and teams must balance efficiency and accuracy.
Different components, such as weights and activations, often require different handling strategies. As a result, modern quantization pipelines often combine multiple techniques or hybrid strategies across different parts of a model.
What actually works on mobile
Not all quantization methods are equally practical for mobile deployment. Their effectiveness depends on runtime support, model architecture, and latency constraints. In practice, the goal is to balance accuracy, simplicity, and hardware compatibility rather than chasing maximum compression.
8-bit PTQ remains the most reliable default, thanks to broad support across runtimes like LiteRT, ONNX, and ExecuTorch, along with highly optimized Arm CPU kernels. It typically reduces memory and bandwidth with minimal accuracy loss, which makes it a solid baseline for production. In practice, not all layers are quantized. Some large and sensitive components, such as the initial embedding layer, can significantly degrade output quality when precision is reduced.
For further compression, weight-only 4-bit approaches such as W4_AFP16 using techniques like Activation Aware Quantization (AWQ) provide a practical next step. These approaches preserve critical weights while compressing less sensitive weights. More advanced methods can enable stable INT8 pipelines by handling activation outliers without runtime cost. These methods are discussed later in this blog.
In production, hybrid strategies often work best, as some components like attention and output layers are more sensitive to reduced precision. Success depends on aligning the quantization method with both the runtime and hardware. Even the most effective technique provides little value if the platform cannot execute it efficiently.
Different quantization approaches for LLMs
Quantization techniques have advanced significantly in recent years. PTQ methods such as SmoothQuant, QRONOS, and TurboQuant address quantization errors caused by weight and activation outliers. A notable trend is the use of mathematical transformations, particularly scaling and rotation-based methods. These techniques redistribute large outliers across channels, making models significantly more robust to low-precision representations. However, this blog focuses on more standard approaches for quantization. These techniques are well supported by existing tooling and deliver strong results for most mobile AI workloads.
PTQ vs QAT and what matters for mobile
PTQ and QAT offer two approaches to reducing model size and improving efficiency, particularly for mobile deployment. PTQ converts an existing FP32 or FP16 model to lower precision such as 8-bit or 4-bit, without retraining. This often uses hybrid schemes where weights are compressed but activations remain at higher precision. This helps balance accuracy and performance however, it struggles with sensitive components such as attention layers and dynamic activations with outliers. These mixed precision types are often denoted in a format like W4_AFP16, which represents INT4 weights and FP16 activations.
In contrast, QAT simulates quantization effects during training. This enables the model to adapt to low precision representations and often achieve higher accuracy, especially at aggressive bit-widths. Techniques such as QLoRA build on this approach. However, QAT increases training complexity and infrastructure requirements, making PTQ more practical for quick deployment on mobile devices. QAT is best suited for deployments where accuracy on resource-constrained mobile devices is critical and where high-quality datasets are available.
Static versus dynamic quantization
Static and dynamic quantization are two post-training techniques that reduce model size, each with different trade-offs for mobile deployment. Static quantization precomputes quantization parameters for weights and activations using a calibration dataset. This enables efficient inference with no runtime overhead, making it ideal for stable, predictable inputs such as camera pipelines. However, it can be sensitive to poor calibration and changes in data distribution. In contrast, dynamic quantization pre-quantizes weights but computes activation ranges at runtime. This removes the need for calibration data. It can adapt more effectively to variable or unpredictable inputs, such as NLP or multi-domain assistants, though it typically offers fewer performance gains due to added runtime computation.
4-bit vs 8-bit precision
For mobile and edge deployments, 8-bit and increasingly 4-bit quantization for weights and activations are widely supported by hardware and inference runtimes. In practice, larger language models can outperform smaller models at higher precision, even when aggressively quantized.
As a result, the industry is investing more in low-precision integer support across Arm CPUs, GPUs, and NPUs, enabling efficient execution of these models on-device. Today, 8-bit quantization is the industry standard for non-GenAI models, and there is strong ecosystem support. On Arm CPUs, libraries such as KleidiAI further accelerate GenAI models, while mobile runtimes are heavily optimized for INT8 and INT4 execution. This enables developers to deploy more capable models while benefiting from a 4× reduction in model size compared to FP32, with minimal impact on accuracy.
4-bit quantization takes this a step further by targeting memory bandwidth and model size constraints. Support for INT4 is improving rapidly, with libraries such as KleidiAI increasingly optimized for lower-bit workloads and even supporting 2-bit weight quantization. AngelSlim is a recently released 2-bit model that has achieved strong results with extreme compression. This makes it possible to run larger and more capable models on mainstream mobile devices, particularly in scenarios where memory bandwidth is the primary bottleneck.
In practice, this enables developers to trade numerical precision for model capacity. They can deploy more aggressively quantized models to enable higher-quality on-device AI experiences if accuracy is carefully validated for the target use case. Fine-tuning can also help recover model quality after aggressive quantization. However, it increases complexity and depends on access to high-quality data.
Beyond data type changes, newer techniques are emerging to address some of the challenges related to LLMs.
Applying quantization approaches on Arm devices
To help mobile developers understand on-device performance, we benchmarked and evaluated Gemma-3 models and Gemma-4-E2B. We ran these models on a single device with and without Scalable Matrix Extension-2 (SME2) enabled. SME2 is a recent CPU extension on Arm Lumex CSS and accelerates matrix-oriented compute workloads. You can find more details on the technologies page. When evaluating or deploying newer models such as Gemma-4-E2B, keep in mind that tooling support takes time to matures. At the time of publication, LiteRT, PyTorch, and ONNX did not support all quantization methods for these models. As a result, we could not evaluate every available approach. LLM deployment on mobile and edge devices is rapidly changing and iterating, with both new quantization approaches and runtime APIs.
Understanding on-device runtimes
Quantizing a model alone does not guarantee performance gains. Performance also depends on whether the runtime can efficiently execute the quantized format. This requires support for low-precision data types and access to optimized kernels mapped to the target hardware such as CPUs, GPUs, and NPUs. Runtimes like LiteRT, ONNX, and ExecuTorch address this challenge by dispatching operations to prebuilt kernels, often relying on libraries like Arm’s KleidiAI to provide highly optimized implementations for low-precision workloads. Hardware features such as Arm’s SME2 can further improve performance by accelerating kernel operations on-device.
Benchmark results varied depending on model architecture and sensitivity to reduced precision. For example, 8-bit and even 4-bit weight quantization often maintained acceptable performance. However, reducing activation precision to INT8 led to significant degradation in some cases, including incoherent outputs. This behavior is discussed in detail in this paper but is outside the scope of this blog. These results show that quantization strategies are not universally transferable, and successful deployment typically requires model-specific tuning and a balanced approach to precision across different components.
Measuring the performance
To understand on-device performance on Android, we benchmarked Gemma models with different quantization methods. We want to answer the following questions:
- How does performance change for different quantization approaches?
- What sort of performance do we achieve when running these LLMs on SME2-enabled devices?
To understand model performance, we consider the following metrics:
- Prefill TPS
- Decode TPS
- Perplexity
- Massive Multitask Language Understanding (MMLU) Benchmark
Performance comparison
To evaluate different quantization strategies, we measured model quality using perplexity on WikiText-2 in the llama.cpp framework, and where possible, MMLU for general accuracy. We used base, non-instruction-tuned models to ensure reliable perplexity comparisons, as instruction tuning can skew token predictability. We measured performance on a single device and benchmarked with and without SME2. Using LiteRT, we averaged results over 5 runs and controlled for thermal throttling. Some evaluation frameworks still have tooling gaps, specifically for newer released models like Gemma-4-E2B. However, these benchmarks can still provide a practical view of real-world performance.
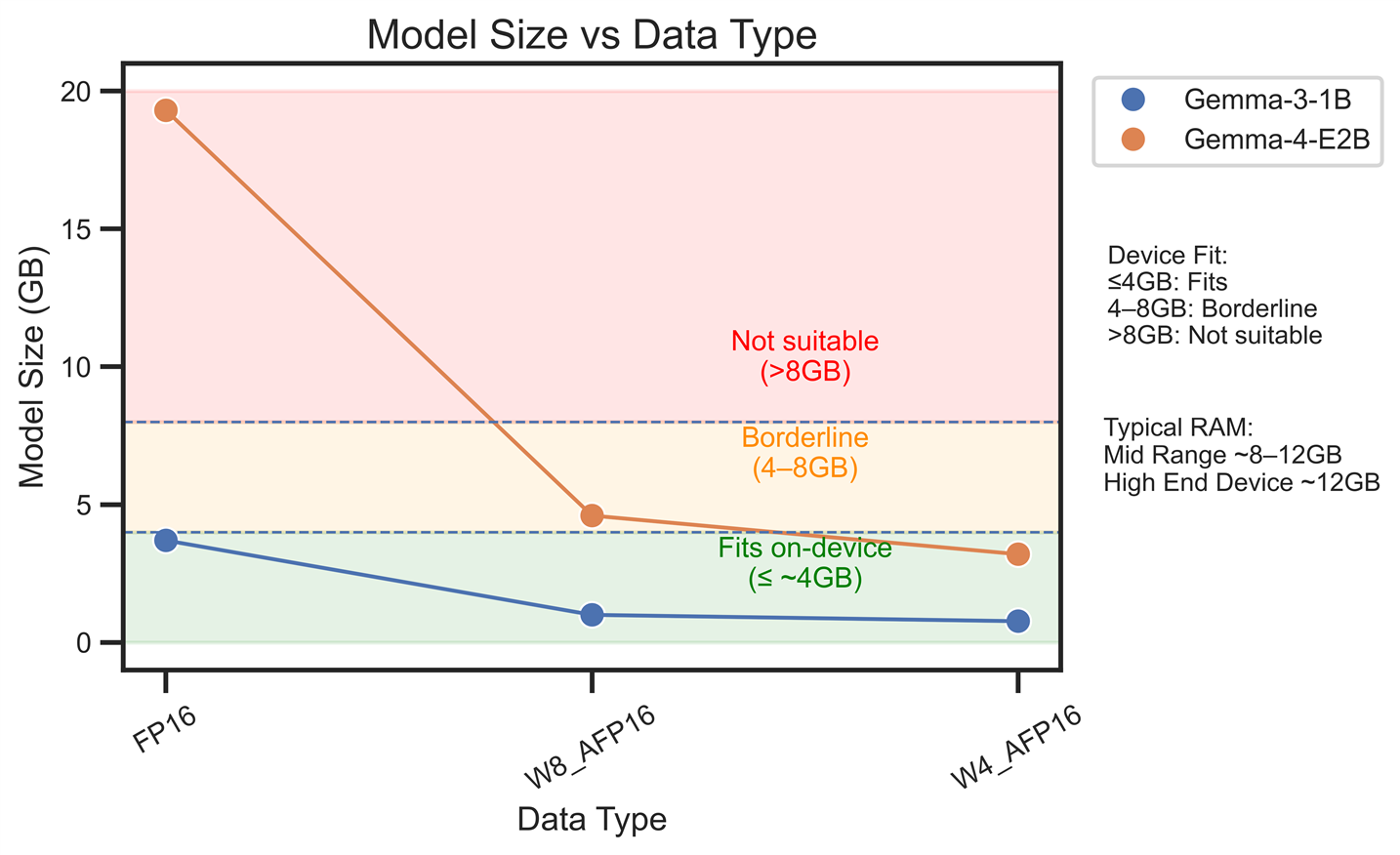
Figure 2: Shows the model size as a function of different data types
Figure 2 compares model size across different quantization strategies for Gemma-3-1B and Gemma-4-E2B models, highlighting the significant impact of weight compression techniques on portability. In FP16 format, model sizes are largest; Gemma-3-1B requires 3.7 GB and Gemma-4-E2B requires 19.3 GB. Quantization methods such as INT8 and especially INT4 reduce memory footprint substantially, down to approximately 0.77 GB for Gemma-3-1B and 3.2 GB for Gemma-4-E2B. Figure 3 shows that this reduction in size causes only minor changes in perplexity while delivering large performance improvements. These results suggest that lower-precision representations retain most of the model’s quality. In early testing of Gemma-3, we saw that more aggressive model compression caused model failure and produced incoherent responses. This was especially true when activations were compressed. You can find more information here. The graph illustrates the key trade-off. Aggressive weight quantization can improve on-device feasibility with small accuracy degradation, making smaller models and lower-bit formats more suitable for edge deployment scenarios.
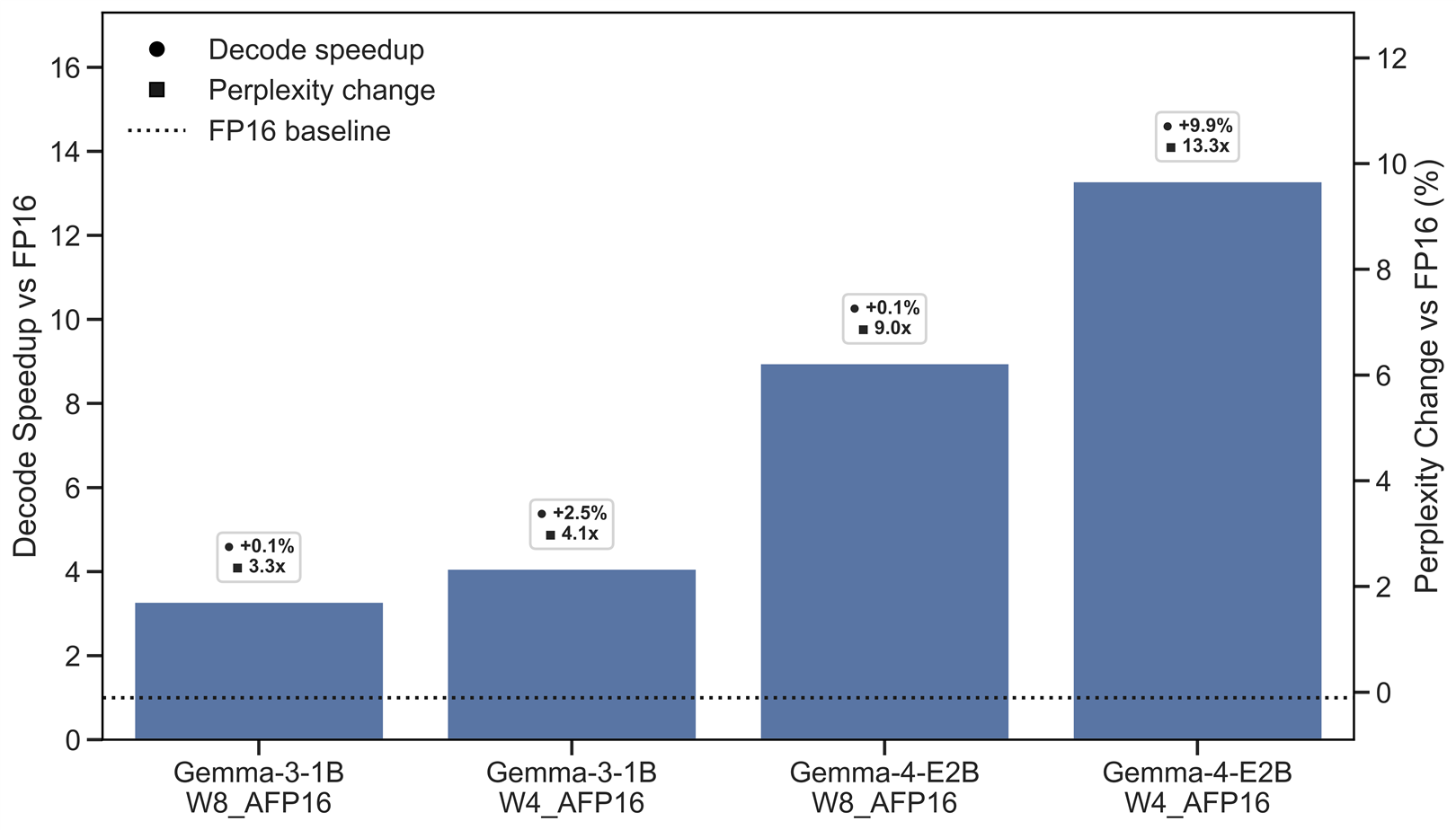
Figure 3: Shows the impact of different datasets on perplexity for Gemma-3-1B and Gemma-4-E2B. A larger positive perplexity indicates lower quality.
We can also plot prefill tokens per second (TPS) and decode TPS. These metrics show how fast the model can process information during prefill and generate output during decode. Prefill performance is usually constrained by memory bandwidth and compute throughput. GPUs and NPUs can process many operations in parallel and as a result, prefill TPS is often much higher on these accelerators. The decode metric reflects the efficiency of KV cache access, memory latency, and sequential execution. Comparing these numbers can help identify where the bottlenecks are when running LLM workloads. It is often useful to compare the ratio of prefill TPS to decode TPS. A high ratio typically indicates strong parallel compute capability, which is common on NPUs and GPUs, whereas a low ratio indicates LLM workloads running in a more constrained environment with limited parallelism.
Figure 4(a) and 4(b) compare prefill TPS for Gemma-3-1B and Gemma-4-E2B with and without SME2. With SME2 enabled, prefill TPS increases all quantized data types.
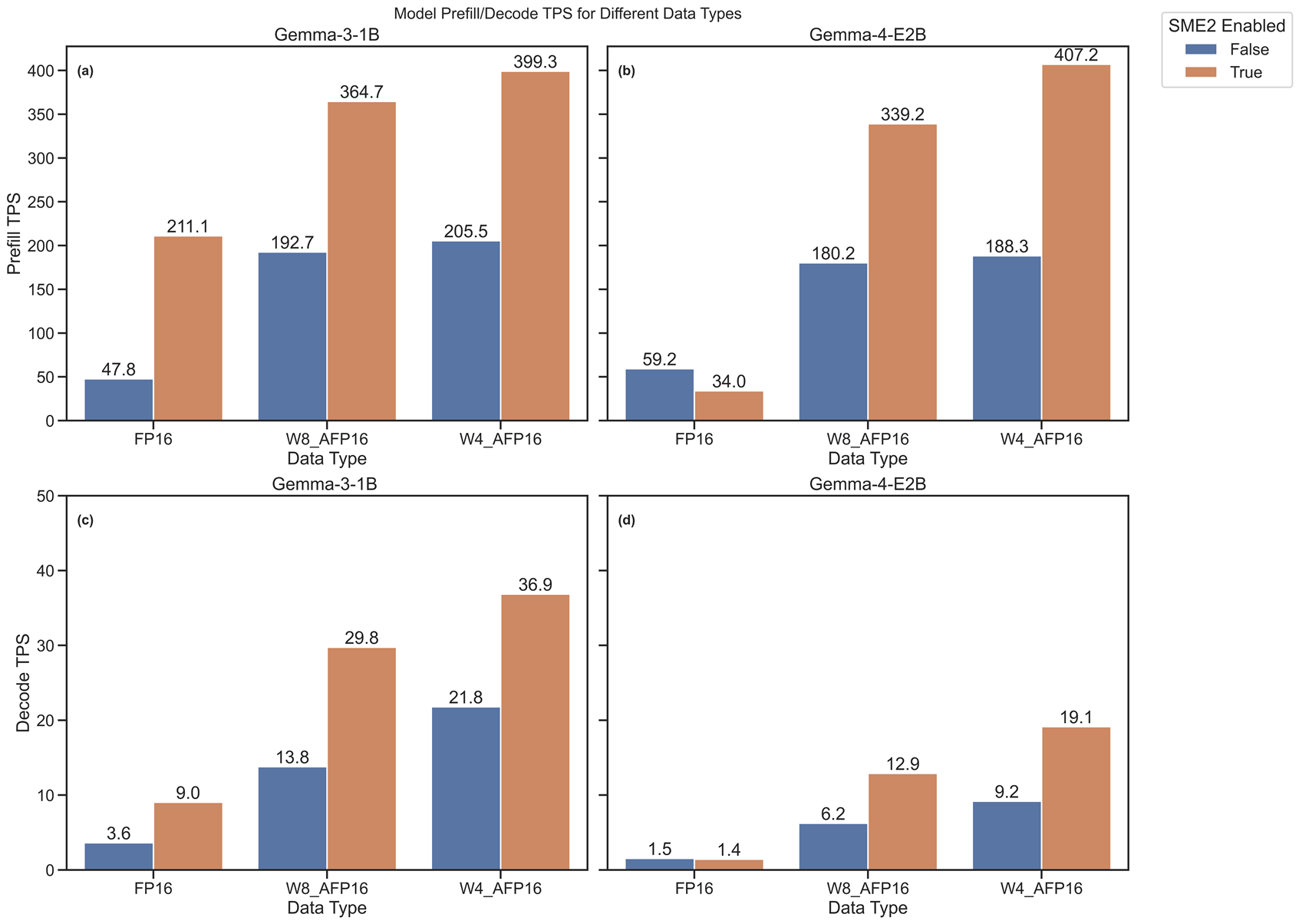
Figure 4: Indicates the model prefill/decode TPS for different data types across Gemma-3-1B and Gemma-4-E2B running on a single CPU thread.
Figures 4(c) and 4(d) show the decode TPS for Gemma-3 and Gemma-4-E2B. For a single thread, SME2 improves performance across most data types, with the exception of Gemma-4-E2B in FP16.
Tables 2 and 3 show the LiteRT-LM performance results, and Table 4 shows the model quality results from llama.cpp. We calculated these numbers by using a prompt text file containing 512 tokens and 128 decode tokens.
Table 2: Performance results from SME2 benchmarking on Gemma-3-1B.
|
Data Type |
Prefill TPS (SME2 On) |
Prefill TPS (Off) |
Decode TPS (SME2 On) |
Decode TPS (Off) |
|
FP16 |
211.11 |
47.75 |
9.04 |
3.63 |
|
W8_AFP16 |
364.71 |
192.65 |
29.76 |
13.80 |
|
W4_AFP16 |
399.26 |
205.46 |
36.86 |
21.80 |
Table 3: Gives an overview of the performance results from SME2 benchmarking on Gemma-4-E2B.
|
Data Type |
Prefill TPS (SME2 On) |
Prefill TPS (Off) |
Decode TPS (SME2 On) |
Decode TPS (Off) |
|
FP16 |
34.01 |
59.24 |
1.44 |
1.54 |
|
W8_AFP16 |
339.16 |
180.31 |
12.91 |
6.23 |
|
W4_AFP16 |
407.17 |
188.31 |
19.15 |
9.19 |
Table 4: Model Quality comparison between Gemma-3-1B and Gemma-4-E2B.
|
Model |
Data Type |
Perplexity |
MMLU% |
Model Size GB |
|
Gemma-3-1B |
FP16 |
10.79 |
39.09 |
3.7 |
|
Gemma-3-1B |
W8_AFP16 |
10.801 |
38.85 |
1.0 |
|
Gemma-3-1B |
W4_AFP16 |
11.06 |
35.97 |
0.77 |
|
Gemma-4-E2B |
FP16 |
8.32 |
Not Supported |
19.3 |
|
Gemma-4-E2B |
W8_AFP16 |
8.33 |
Not Supported |
4.6 |
|
Gemma-4-E2B |
W4_AFP16 |
9.014 |
Not Supported |
3.2 |
Across both Gemma models, quantization improves efficiency with relatively small impact on model quality. For Gemma-3-1B, 8-bit quantization has almost no impact on perplexity, while 4-bit shows a minor degradation in model quality. However, the 4-bit model comes in at just under 1 GB. Gemma-4-E2B follows a similar trend, with the 8-bit model performing similarly to FP16 and only a slight degradation in performance for the 4-bit model. The results also show that a larger 2B-parameter model with aggressive quantization can deliver better quality than a smaller full-precision model.
Interpreting the benchmark results
The benchmark results highlight that quantization makes deployment on mobile devices more practical with minimal loss in model quality. The new Gemma models are highly resistant to accuracy loss. 8-bit quantization remains a strong default. It delivers near-FP16 accuracy while reducing model size and improving performance, while 4-bit weight quantization reduces memory requirements even further but with only a small drop in performance. Support for lower-precision workloads continues to improve with libraries such as KleidiAI providing optimized implementations for Arm-based CPU workloads.
Weight quantization alone was broadly successful however, aggressive activation quantization led to significant model instability. In practice, hybrid approaches produced the best results. These approaches aggressively compress weights while keeping activations at a higher precision. New quantization techniques such as TurboQuant and SmoothQuant aim to support activation compression, but the tooling is still evolving. Our results show that quantization is not a one-size-fits-all solution.
Conclusion
Quantization is becoming a key enabler for bringing large language models onto edge devices. Reducing numerical precision helps developers compress models and reduce compute and memory requirements. This makes it possible to run increasingly intelligent and capable models directly on-device. This approach can improve privacy, reduce latency, and lower operating costs for mobile developers, as well as a more responsible user experience.
However, quantization is not a simple compression step. LLMs are highly sensitive systems, and pushing compression too far, especially for activations, can lead to unstable or degraded model performance. In practice, hybrid strategies often outperform aggressive overall quantization. We found that compressing weights to 8-bit or 4-bit precision while keeping activations at FP16 provides a strong balance between model quality and size. This approach also enables deployment on many mid- to high-tier devices. Research in quantization is rapidly evolving and has shown that while weight quantization is robust, activation quantization is still one of the hardest challenges for mobile and edge AI deployment. For most mobile developers, 8-bit PTQ remains the most practical starting point as it offers strong performance with minimal quality loss. When additional compression is required, 4-bit weight quantization is a natural next step, particularly on memory-constrained devices. Our results also demonstrate that larger Gemma-4-E2B models can outperform smaller models running at higher precision at the cost of increased on-device memory.
At the same time, the ecosystem and frameworks are evolving quickly. Newer techniques such as SmoothQuant, AWQ, and TurboQuant continue to expand the capabilities of quantization, while hardware and Arm runtimes continue to improve support for low-precision execution. However, success in real-world deployments still depends on multiple factors. To achieve the best performance and efficiency, the model, quantization strategy, inference runtime, and hardware must work together. There is no single quantization strategy that works for every deployment, and the best strategy depends on the use case, model, and target device. As quantization techniques mature and mobile hardware evolves, increasingly capable models will run entirely on-device. Techniques that are still emerging today are becoming practical deployment options and bring us closer to a future where intelligent, private, and always-available AI runs on-device.
If you want to learn more about quantization, Arm Community provides several learning paths and blogs. You can read a recent blog about training, quantization, and deployment on Ethos-U85, as well as a learning path that shows how to quantize to INT4. Explore the currently supported KleidiAI micro-kernels here. You can also read a joint Arm and Google blog about methods for accelerating on-device AI here.

Re-use is only permitted for informational and non-commercial or personal use only.
