Mali and Unreal Engine’s Nanite: Enabling the future of mobile graphics
Nanite demonstrates that GPU-driven rendering works on mobile. Learn how Mali GPUs handle complex geometry and modern pipelines

Nanite as an example of new rendering pipelines
Computer graphics, video games, and real-time 3D content are evolving rapidly. Game developers continue to push graphics further. The industry is now adopting more GPU-driven workflows and advanced rendering techniques such as Unreal Engine’s Nanite virtualized geometry system.
Many assume these techniques are exclusive to desktop and console systems. This blog post shows how Tile-Based Rendering GPUs like Mali also benefit from techniques like Nanite.
Geometry complexity has increased significantly. Modern assets often contain millions of triangles. Traditional solutions such as level-of-detail (LoD) systems introduce added work for artists. They can cause visible popping and struggle to cope with the growing geometry complexity.
Nanite attempts to address this challenge. It is a bold example of a complex technique built on GPU-driven ideas. Traditionally CPU-based operations, such as culling, LoD management, visibility checks, and draw call handling, are moved from the CPU to the GPU. Nanite can render scenes with an extremely high triangle count. Nanite highlights both the benefits and the challenges of this new rendering paradigm. It represents part of a broader transition to GPU-orchestrated rendering. GPU-driven rendering extends well beyond a single technique like Nanite. It represents the future of rendering, and Mali is ready to empower developers to adopt these new techniques on mobile devices.
Enabling Nanite on Android devices with Mali GPUs
Hardware capabilities
Older mobile GPUs and drivers lack several key features required by Unreal Engine 5’s Nanite implementation. As a result, Nanite cannot run on mobile devices out of the box. Mali GPUs have provided the key functionality Nanite requires for some time. Capabilities such as dispatch and draw indirect are standard Vulkan features. These features enable GPU-driven techniques on most existing hardware. VK_KHR_shader_image_atomic_int64 has also been supported by Mali drivers for some time.
More recently, Mali drivers support for VK_KHR_compute_shader_derivatives This feature improves texture quality in compute shading. With this support, Mali now provides everything required for running Nanite.
Unreal Engine requirements
Unreal Engine manages GPU capabilities through Shader Models. These models are distinct from DirectX Shader Models and control scalability features. Unreal Engine divides its rendering systems into multiple tiers. These tiers include the mobile renderer and the desktop renderers. Desktop renderers are further divided into Shader Model 5 (SM5) and Shader Model 6 (SM6). Nanite requires SM6 by default.
Unreal Engine does not officially support SM6 on Android. This means Nanite cannot run out of the box. However, the latest Mali GPUs can run Nanite. Developers who want to experiment have two main options:
- SM6 on Android: Support for SM6 on Android can be added through engine modifications. To achieve this, you need to edit a few files. First, define a new shader model in DataDrivenPlatformInfo.ini. Then create a new Vulkan profile in VP_UE_mobile_vulkan.json. These can be based on the SM6 model for Vulkan-PC, with certain features disabled if they are not needed for Nanite. We also suggest reviewing all C++ references to SM5_Android and SM6, updating them to support SM6_Android. This update may require additional C++ changes to adjust or refine specific features. For example, support for subgroup operations is not required for all shader stages.
- Nanite on SM5 on Android: Nanite can be enabled on SM5 by adjusting the options of the SM5_Android shader model in DataDrivenPlatformInfo.ini and adding support for atomics to the SM5_Android vulkan profile. Unreal Engine also contains C++ code checks for Nanite and other feature requirements. Update these checks as needed.
Nanite is not supported on the mobile renderer. It is only available on desktop renderers. Mali continues to improve in performance and its ability to handle high-end content. However, developers should exercise caution when targeting mobile devices with desktop renderers. These renderers are not optimized for mobile platforms. We recommend that developers target R49. Older drivers need additional care. These drivers require a shader workaround because certain Nanite bit operations can trigger driver bugs.
How Nanite works
We recommend that engine developers interested in Nanite review Unreal Engine documentation and previous material from Epic. These resources provide a comprehensive deep dive. Here, we provide a concise overview, as Nanite offers valuable insights into important rendering concepts.
Pipeline breakdown
- Render non Nanite geometry using the traditional a vertex-fragment pipeline.
- Perform GPU-based cluster culling using the previous Z-buffer and selecting the appropriate LoD.
- Classify and allocate visible clusters into rasterization bins.
- Build a visibility buffer with 64-bit atomics:
- Small triangles → rasterized via compute-based rasterizer.
- Large triangles → rasterized with fixed-function hardware.
- Re-run against the current Z-buffer (most triangles are already rasterized, so this produces very little work).
- Classify and allocate visible pixels into shading bins.
- Shade via compute shaders.
This design refines the traditional pipeline by moving operations to the GPU and increasing their granularity. It provides a strong case study for a GPU-driven future.
Nanite on Tile-Based Renderers: Mali’s advantage
A common misconception is that complex rendering pipelines are only suited to immediate mode desktop GPUs. However, Mali’s Tile Based Rendering (TBR) architecture fully supports techniques such as Nanite. It delivers both high performance and energy efficiency.
Nanite performance on Mali
To evaluate Nanite on Mali, we updated Mori, an internal Unreal Engine demo. We replaced the trees and other meshes in the scene with new assets that have higher vertex densities. Nanite allows us to run the current version of the demo, while disabling Nanite causes the demo to crash on startup.
The updated scene renders over six million visible triangles, with even more before culling. We are still able to maintain our 30 FPS target. When designing the content, we selected a target frame rate. Simpler scenes can easily exceed 100 FPS. However, we chose a more realistic scenario by increasing geometric complexity and targeting 30 FPS, a common choice among developers.
It is important to note that Nanite performance depends on many factors beyond the number of visible triangles. Occluded geometry, material complexity, lighting and shadows, and how well a mesh is subdivided into clusters all play a significant role.
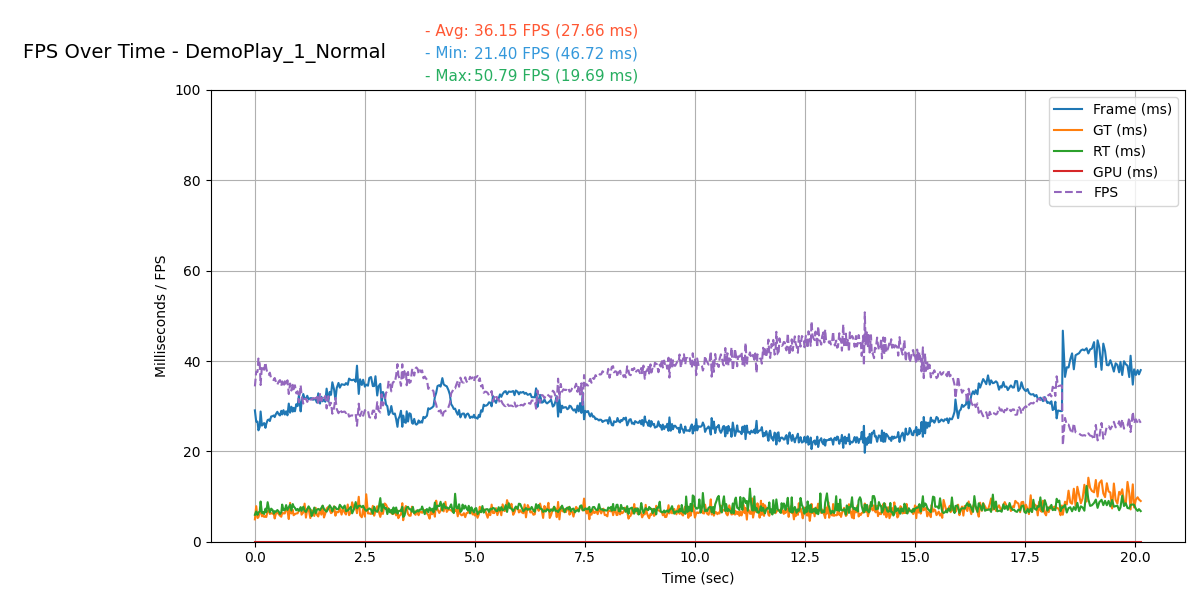
When we decided to update the scene to use Nanite, we needed to determine the performance limits. To do this, we created a series of tests using proxy geometry. These tests allowed us to set budgets for the final scene. The tests provided valuable insights into how Nanite operates and helped us better understand its behavior. They also offered a useful performance comparison.
Nanite maintains strong performance even at high triangle counts. The 30K version uses our original meshes. We removed the alpha mask to avoid the costly Pixel Programmable materials. However, the original mesh still performed poorly due to its disjoint geometry.


| Triangles per tree mesh | Maximum rendered triangles | Average time without Nanite | Average time with Nanite |
| 30K | 1.2M | 29.67 ms (33.71 FPS) | 23.83 ms (41.96 FPS) |
| 76K | 2.2M | 37.40 ms (26.74 FPS) | 22.75 ms (43.96 FPS) |
| 634K | 18M | 199.36 ms ( 5.02 FPS) | 26.16 ms (38.23 FPS) |
Cluster culling efficiency
Traditionally, the CPU performs culling on a per-mesh basis. Nanite changes this approach. It divides meshes into clusters, sometimes called meshlets. This enables culling to be executed on the GPU at a per-cluster level.
Shifting to cluster-based culling allows Nanite to eliminate far more geometry than traditional techniques. TBR GPUs like Mali have a relatively low vertex throughput. Efficient culling has a particularly positive impact on performance. In fact, a significant portion of Nanite’s performance gain comes from cluster culling. We recommend developers experiment with incorporating it into their engines.
Nanite also extends cluster culling with GPU per cluster LoD selection. This further optimizes performance. Its visibility buffer also uses the previous Z-buffer to reduce the rasterization of non-visible triangles. Rasterizing overlapping triangles typically causes overdraw on most GPUs. Nanite addresses this issue.
Recent Mali GPUs mitigate the problem with Hidden Surface Removal (HSR). HSR uses a hardware fragment pre-pass that optimizes non visible fragments. This may reduce the value of Z-buffer based culling, particularly in simpler implementations that lack Nanite’s compute rasterizer. However, it is important to note that Hidden Surface Removal still performs work to determine whether fragments from culled triangles are visible.
This result shows why rendering is shifting toward GPU-driven techniques. By moving culling, visibility checks, and LoD management to the GPU, Nanite not only achieves finer granularity but also delivers higher performance. GPU-driven techniques provide significant advantages on mobile. We encourage developers to experiment with them.
The following data further illustrates this point. Our test scene contains 5 million rendered triangles. For comparison, we also include results with the compute shader rasterizer disabled. This helps isolate the impact of the visibility buffer and cluster culling. It is important to note that when using the compute rasterizer, metrics such as primitives or overdraw are not captured by GPU hardware counters.

| Name | Time(ms) | GPU active (mega-cycles) | GPU visible primitives (mega-primitives) | GPU input primitives (mega-primitives) | Overdrawn (milli-threads) | |||||
| No Nanite | 0.25 | 100.0% | 232.1 | 100.0% | 1.833 | 100.00% | 58.67 | 100.00% | 0.183 | 100.0% |
| Nanite (only hardware rasterizer) | 0.10 | 39.5% | 88.6 | 38.1% | 0.911 | 49.70% | 10.17 | 17.33% | 0.112 | 61.21 |
| Nanite (HW and Compute Shader/ Software rasterizer) | 0.04 | 15.7% | 35.1 | 15.1% | 0.006 | 0.31% | 0.03 | 0.04% | 0.106 | 57.9 |
Compute rasterizer
The benefits of Nanite extend beyond its GPU-driven design. A key feature of Nanite is its software rasterizer. This rasterizer uses a compute shader to process micro-triangles. Mali GPUs include a powerful hardware rasterizer. At first, it may seem counterintuitive to replace it with a compute shader. Compute shaders typically deliver lower performance than a hardware implementation. However, hardware rasterizers are optimized for large triangles They often struggle with small or thin triangles.
Nanite overcomes this limitation with a hybrid approach. Large triangles are efficiently processed by the hardware rasterizer via a vertex-fragment pipeline. A compute shader rasterizes small triangles to avoid these inefficiencies. The previous table shows performance gains when the software rasterizer is enabled.
A common challenge artists often spend time optimizing is quad overdraw. On Mali, as on most GPUs, fragments are shaded in quads. Micro-triangles that do not cover a full quad generate unnecessary fragments that are ultimately discarded. Nanite addresses this problem by using a compute shader to rasterize these problematic cases.
Tile-based GPUs like Mali also struggle with thin, elongated triangles. Long, thin triangles can span multiple tiling bins. This results in significant performance costs. Nanite’s clustering algorithm replaces most of these problematic cases with well-formed triangles. The few remaining ones are efficiently handled by the compute rasterizer.
The following table illustrates this behavior using our Mori scene with proxy geometry assets. We adjust r.Nanite.MinPixelsPerEdgeHW to control the number of triangles sent to the hardware rasterizer. Triangles with an edge smaller than this value are sent to the compute shader rasterizer. Smaller triangles benefit from the software rasterizer. Beyond a certain point the hardware implementation provides a significant advantage.
A key characteristic of Mali GPUs is that fragment and non-fragment work can overlap. Depending on the scene, fine-tuning the balance of triangles rasterized by each method can produce meaningful performance improvements.
| Average triangles per mesh | Time (MinPixelsPerEdgeHW=8) | Time (MinPixelsPerEdgeHW=16) | Time (MinPixelsPerEdgeHW=32) | Time (MinPixelsPerEdgeHW=64) |
| 30K | 25.63 ms | 24.59 ms | 24.17 ms | 24.62 ms |
| 76K | 24.28 ms | 23.39 ms | 22.72 ms | 23.65 ms |
| 634K | 29.57 ms | 28.13 ms | 26.26 ms | 26.95 ms |
Vertex workload scaling
Mali's vertex processing capabilities continue to improve. However, TBR GPUs generally have lower geometry throughput than most desktop GPUs. Nanite helps developers increase the amount of geometry they can push on mobile.
An advantage of Mali is that fragment and non-fragment processing can run in parallel. Proper use of synchronization barriers enables overlapping vertex and fragment workloads and achieving optimal performance. It is important to note that rendering resolution has no performance impact on vertex-bound content. Reducing resolution may therefore not improve performance in geometry heavy scenes. However, Nanite determines LoDs according to cluster screen size. As a result, vertex costs depend on resolution.
With Nanite, performance is closely tied to resolution, even in geometry-heavy scenes. This gives developers a straightforward way to scale performance by adjusting the rendering resolution. Nanite works well with upscaling techniques like Arm Accuracy Super Resolution (ASR) and Neural Super Sampling (NSS). These techniques allow developers to balance visual quality and performance across multiple devices.
The following table presents data from our test scene using placeholder assets. It shows how Nanite content continues to scale with resolution, even in scenes with highly detailed geometry.
| Triangles per mesh | Average time 80% resolution | Average time 50% resolution | Improvement |
| 30K (Nanite) | 23.83 ms (41.96 FPS) | 17.99 ms (55.57 FPS) | 32% |
| 76K (Nanite) | 22.75 ms (43.96 FPS) | 17.93 ms (55.78 FPS) | 21 % |
| 634K (Nanite) | 26.16 ms (38.23 FPS) | 20.48 ms (48.84 FPS) | 22% |
Challenges and optimization opportunities for Mali
Atomic operations
Nanite relies heavily on atomic operations. These operations are used for dynamic memory allocation, and 64-bit atomics are required to resolve the visibility buffer. Mali has supported atomics for some time. However, workloads may still experience suboptimal performance if atomics are not used efficiently. We recommend profiling regularly to check performance.
Empty or small compute passes
GPU-driven pipelines often issue many small or empty dispatches. On Mali GPUs, these workloads can introduce significant overhead. We recommend designing shaders so that each dispatch performs a meaningful amount of work. However, this may not always be possible in GPU-driven scenarios. Frequent profiling helps identify and mitigate these inefficiencies.
Shadows
Ideally, Nanite content should use Virtual Shadow Maps (VSM) to generate shadows. It is technically possible to modify Unreal Engine to enable VSM on Mali-G1 GPUs. However, we do not recommend this as performance will not be optimal due to the lack of hardware support for clip distance. Our Nanite demo instead relies on the default shadow maps. This approach is not ideal, but it provides sufficiently performance in practice.
Compute shading
Mali compute performance continues to improve. However, certain hardware advantages remain unavailable to compute shaders. For example, compute shaders disable bandwidth-saving techniques such as framebuffer compression. We recommend reviewing our compute shading best practices.
Mali can execute multiple types of work simultaneously. It typically overlaps fragment and vertex processing to achieve significant performance gains. However, shifting more work to compute can reduce the opportunity for such overlap. This is especially true when dependencies prevent parallel execution.
Our driver supports compute shader derivatives. Nanite uses this feature to improve texture quality. Mali continues to advance compute performance. However, compute shading remains a challenging area and is not recommended for most situations.
Conclusion: Mali proves mobile is ready for the future
Rendering is becoming increasingly complex. GPU-driven techniques are also becoming more common. PCs and consoles are progressing through this transition. Mobile platforms will follow, unlocking new levels of efficiency, fidelity, and scalability.
With Mali GPUs, this future is already here. Nanite demonstrates that complex rendering pipelines can run effectively on TBR GPUs like Mali. We encourage graphics developers to begin experimenting today. As hardware and drivers evolve, Mali will continue to deliver cutting-edge rendering capabilities to Android devices.

Re-use is only permitted for informational and non-commercial or personal use only.
