perf-libs-sparse: Introducing a new open-source project for sparse linear algebra on Arm
In this blog, we announce perf-libs-sparse, a new open-source project that contains the sparse linear algebra source code included in Arm Performance Libraries.

We are excited to announce that we have created a new open-source project, perf-libs-sparse, which contains the sparse linear algebra source code that goes into Arm Performance Libraries (ArmPL).
This represents the next step of making the component parts of ArmPL available in separate open-source projects, and it follows the existing open-source projects which contain the random number generation and math.h implementations from ArmPL: respectively, OpenRNG and Arm Optimized Routines.
The source code is now publicly available on Arm's GitLab with permissive licences and a self-contained build system. You can find the Documentation in the Arm Performance Libraries Reference Guide.
In this blog, we will also give an overview of why optimized sparse linear algebra functions are important, highlight some recent sparse additions and improvements that were part of the 26.01 release of ArmPL, and discuss what is included in the new open-source project.
What is sparse linear algebra and where is it used?
Vendor maths libraries such as ArmPL all support some optimized sparse linear algebra functions - operations involving matrices and vectors where most of the elements are zero. In contrast with the dense linear algebra support provided by these libraries, the sparse functions take advantage of the memory and time savings to be gained by avoiding the storage and computation of zero-elements. Optimization of sparse matrix operations presents a different challenge compared with dense linear algebra owing to the fact that performance tends to differ based on the sparsity pattern in the matrices as well as the storage format (of which there are many!).
Sparse matrices often appear when creating a discrete model of a continuous mathematical problem, and therefore arise very often in numerical computing. This is especially true for models described as Partial Differential Equations (PDEs) which are used to simulate, for example, fluid flow, electromagnetism and structural mechanics [1].
The solution of PDEs in the form of sparse matrices is also the basis for some Electronic Design Automation (EDA) techniques, where transistor-level circuit simulation is expressed as a linear system of, for example, heat transfer or electromagnetic equations [2]. EDA tools also use sparse matrices away from PDE modelling, as part of SPICE analysis [3].
Sparse operations are also important in the emerging machine learning area of persistent homology, which is a tool in topological deep learning [4].
The importance and prevalence of sparse matrices is reflected in the number and breadth of applications represented by matrices in the SuiteSparse collection, which contains matrices typically used for the testing and benchmarking of sparse libraries.
Recent updates included in ArmPL 26.01
Sparse-times-dense matrix multiplication optimization
ArmPL and perf-libs-sparse work with opaque matrix objects, and, aside from the common sparse matrix formats CSR, CSC, COO and BSR, it is also possible to create dense matrix objects (see our documentation for a description of these formats). This allows for a single matrix multiplication function in the interface which handles any combination of input matrices, including all of the sparse-times-dense options, since we can convert matrices for processing.
CSR times dense is quite a common combination [5] and in ArmPL prior to 26.01 we had no dedicated code path to handle this, so we wanted to see how much performance could be gained by having a kernel for CSR times dense matrix multiplication.
The following chart shows the speedup achieved by the introduction of this dedicated kernel. It is written in C++ in a way that the compiler, GCC or LLVM, can perform auto-vectorization. To benchmark, we have selected cases from the SuiteSparse collection, and multiplied these with a dense matrix whose dimensions match the sparse matrix in its number of rows and having up to 1024 columns. The results in the following chart were collected on an AWS Graviton4 instance using 8 OpenMP threads. Results show at least a 2x speedup following the introduction of the optimised code path, and 4-6x performance improvements in some single precision cases which especially benefit from the efficient use of SIMD instructions in the new kernel.
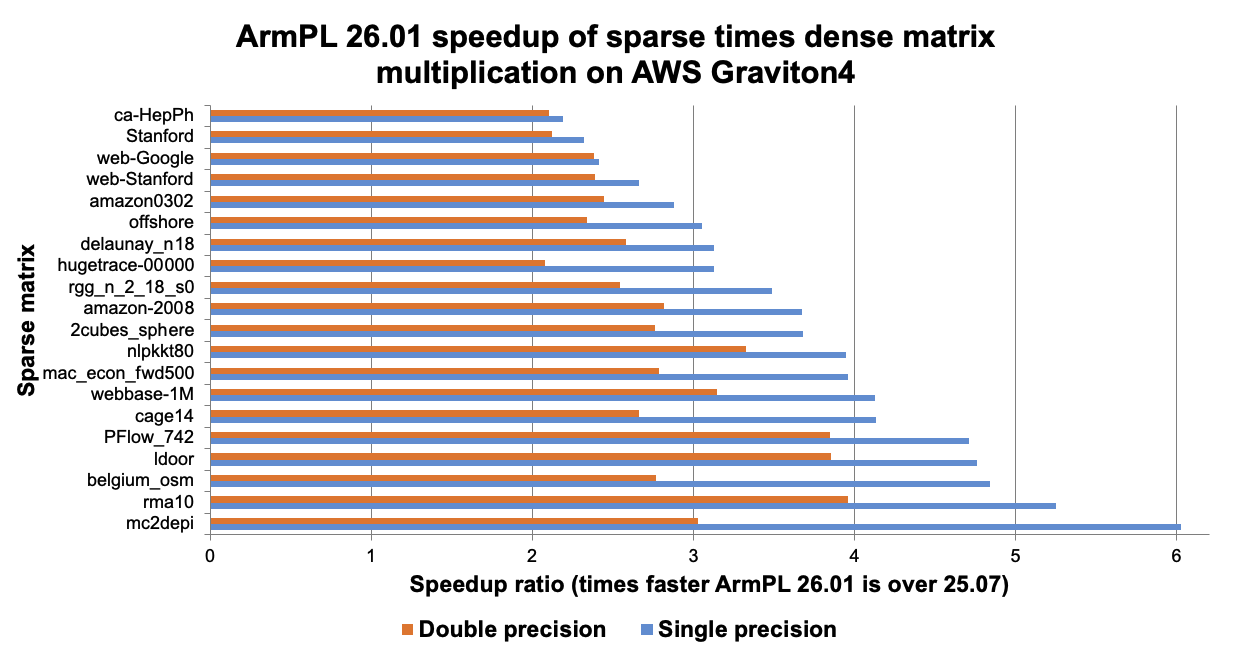
The repository contains a C benchmark program for this sparse-times-dense use case, which can be used along with matrices in the Matrix Market format from the SuiteSparse collection. The compile and link instructions for using either ArmPL or perf-libs-sparse are included in the comments at the top of the file.
Support for supernodal triangular solves
The recent blog about ArmPL 26.01 presented some performance improvements in using the sparse triangular solve functions as part of LDLT factorizations of sparse matrices (the same performance chart is included below). This was achieved through the addition of support for supernodal [6] matrices, enabling a more scalable multithreaded triangular-solve implementation and delivering up to 7x higher performance. This new supernodal sparse matrix support in ArmPL is being adopted to accelerate large sparse linear-system solves in Panua-Pardiso on Arm systems.

The matrices used in these benchmarks are from a 5-point finite difference discretization of Laplace's equation, and only the upper triangular part of the matrix is stored. Laplace's equation is an example of a PDE that is used as a proxy for steady-state diffusion. The resulting matrices are of dimension grid size squared, where the grid is the mesh of points that represents the spatial domain over which we're simulating the diffusion problem. Hence, the smallest grid size in the bar chart (1024) translates into a square matrix with over 1 million rows and columns. With only 3,143,680 non-zero values in the matrix, it has a density of just 0.0003%!
The visualization below represents the connectedness of these matrices. These connectivity diagrams often produce striking, almost artistic patterns, and they can sometimes give an early visual hint about how much parallelism a sparse solver may be able to extract from the problem. The SuiteSparse collection showcases these kinds of graph-based visualizations on its About page. A nice touch!
In the next ArmPL release, we aim to extend our sparse support for these kinds of applications, with sparse triangular solve functionality for both single and multiple right-hand sides.
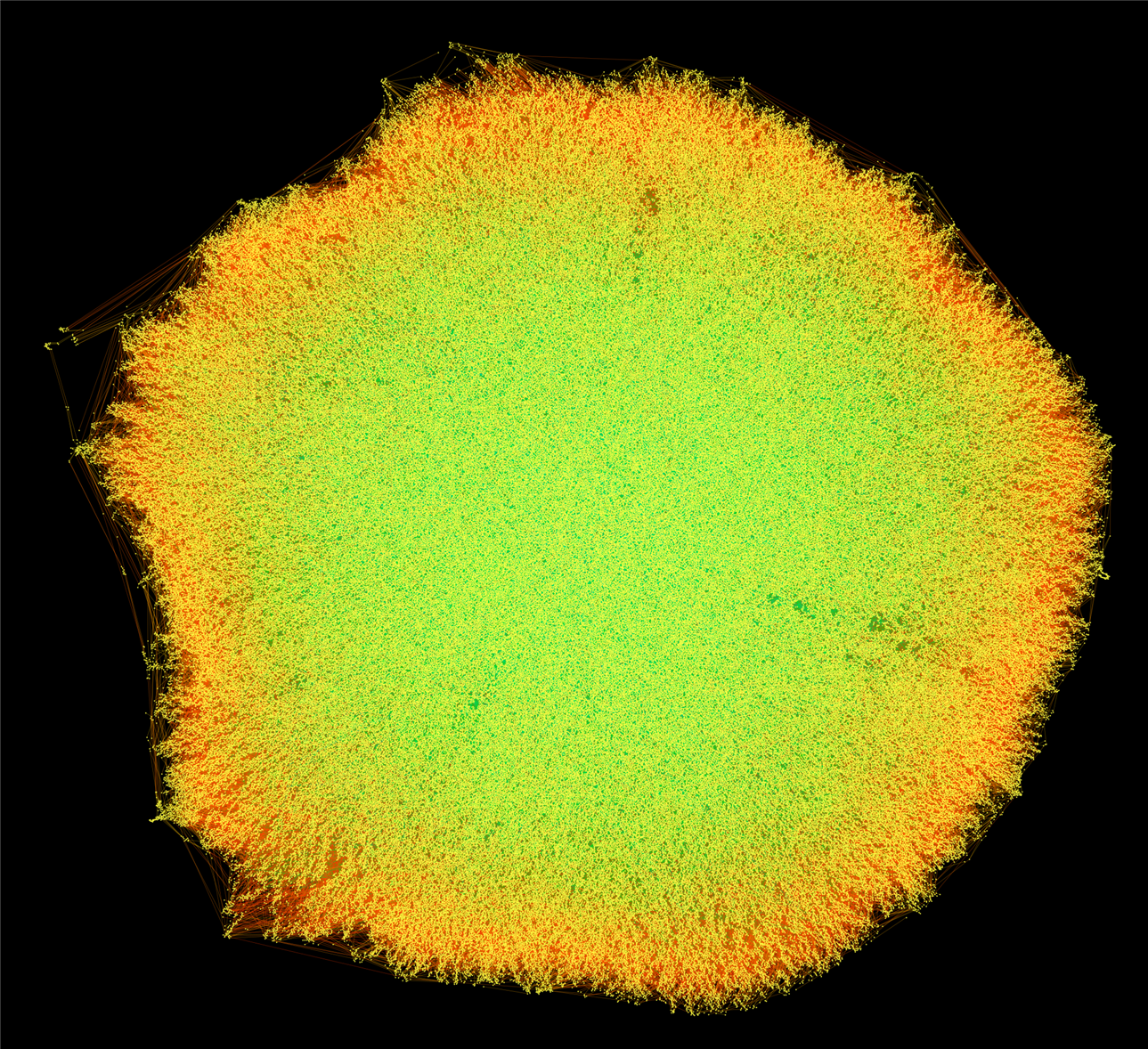
Image: Copyright Olaf Schenk.
What's in perf-libs-sparse?
The new open-source project contains all of the same sparse linear algebra functionality as ArmPL itself, covering the key algorithms and sparse matrix formats which are used in practice. We provide Arm-optimized implementations of sparse matrix-vector multiplication, matrix-matrix multiplication and addition, element-wise matrix multiplication, triangular matrix solve, a selection of sparse vector operations, and utility functions to manage the lifetime of sparse matrix and vector objects. For the full list of functionality covered see the per-function documentation in the ArmPL reference guide. The API follows an inspector-executor model in which users create opaque objects which may have structure converted internally as part of an optimization step.
The implementations in the library are written in C++, but the public interfaces are for C and Fortran bindings (matching those in ArmPL). There are some Fortran tests which are mostly interface correctness checks rather than stringent numerical tests, and there is a suite of C tests which features mostly small problems but does include numerical checks. Most of the sparse validation tests we run before releasing ArmPL have remained downstream due to the cost and complexity of moving them into perf-libs-sparse. Hence adding new tests in the open-source repository is one area where we'd love to see some contributions to increase coverage within the open-source project.
The first thing to note about the source code is that we've changed the public API so that everything is prefixed with perflibs_ rather than armpl_. This is to allow a clear distinction between dependencies on builds of perf-libs-sparse (which may have been customised) and dependencies on ArmPL (which is fixed as it is released as a binary product). However, this is only a superficial difference - see the example benchmark code for sparse matrix times dense matrix operations; that shows how users may easily switch between using the two libraries.
The README.md file contains a description of the dependencies you'll need to install before building perf-libs-sparse for yourself - these are minimal! - as well as the build instructions, which should be very familiar if you've used CMake before. Building the library should take seconds on most systems.
The CONTRIBUTING.md file features a description of the layout of the source code for anyone wishing to contribute; this should be read in the context of the public API, which remains documented in the Arm Performance Libraries Reference Guide.
The repository contains a CMake build system which works on the three platforms supported by ArmPL: Linux, macOS and Windows, with options to enable OpenMP for parallelism (and more!).
One potentially confusing dependency of perf-libs-sparse is on a CBLAS library. CBLAS is the standard C interface to the (Fortran) dense BLAS (Basic Linear Algebra Subroutines). CBLAS functions are provided by vendor libraries such as ArmPL, and hence perf-libs-sparse has a dependency on ArmPL itself by default. Alternatively, there is also an option to link to OpenBLAS to satisfy this CBLAS dependency. See the README.md file for details. In the code the CBLAS function dependencies are isolated in the cblas_wrappers.hpp file.
There is another dependency worth explaining. The project contains a machine directory with code that gets built into a library to understand certain questions about the Arm hardware on which it is intended to be executing. Currently this is simply answering the question "are we using SVE?" but more options may be required in the future. When builds are integrated into ArmPL this dependency is satisfied by separate host system runtime detection code, which is not part of perf-libs-sparse. Instead, perf-libs-sparse has some simple code that is currently controlled by build options rather than runtime decisions.
Conclusion
Sparse matrices are at the heart of many important workloads, from PDE-based simulation and EDA to emerging areas of machine learning. As these problems are widespread, efficient sparse linear algebra can make a real difference to performance across a broad range of applications. With perf-libs-sparse, we want to help grow the ecosystem around sparse computing on Arm by making this code available in the open. We hope this makes it easier for others to explore, benchmark, extend and improve these routines. Patches are welcome!
References
[1] Yousef Saad, Iterative Methods for Sparse Linear Systems, 2nd ed., SIAM, Philadelphia, 2003, Chapter 2: “Discretization of Partial Differential Equations,” pp. 45–72. DOI: 10.1137/1.9780898718003.ch2.
[2] Nityanand Rai, “A Technical Survey of Sparse Linear Solvers in Electronic Design Automation,” Journal of Circuits, Systems and Computers, 2026. DOI: 10.1142/S0218126626500945.
[3] Timothy A. Davis and E. Palamadai Natarajan, “Sparse Matrix Methods for Circuit Simulation Problems,” in Bastiaan Michielsen and Jean-René Poirier (eds.), Scientific Computing in Electrical Engineering SCEE 2010, Mathematics in Industry, vol. 16, Springer, Berlin, Heidelberg, 2012, pp. 3–14. DOI: 10.1007/978-3-642-22453-9_1.
[4] Zhe Su, Xiang Liu, Layal Bou Hamdan, Vasileios Maroulas, Jie Wu, Gunnar Carlsson, and Guo-Wei Wei, “Topological Data Analysis and Topological Deep Learning Beyond Persistent Homology: A Review,” Artificial Intelligence Review, vol. 59, no. 2, article 58, 2026. DOI: 10.1007/s10462-025-11462-w. PMCID: PMC12931839.
[5] Xiaobo Lu, Jianbin Fang, Lin Peng, Chun Huang, Zidong Du, Yongwei Zhao, and Zheng Wang, “Mentor: A Memory-Efficient Sparse-dense Matrix Multiplication Accelerator Based on Column-Wise Product,” ACM Transactions on Architecture and Code Optimization, vol. 21, no. 4, article 79, pp. 79:1–79:25, 2024. DOI: 10.1145/3688612.
[6] Matthias Bollhöfer, Olaf Schenk, Radim Janalík, Steve Hamm, and Kiran Gullapalli, “State-of-the-Art Sparse Direct Solvers,” in Parallel Algorithms in Computational Science and Engineering, edited by Ananth Grama and Ahmed H. Sameh, Birkhäuser, Cham, 2020, pp. 3–33. DOI: 10.1007/978-3-030-43736-7_1.

Re-use is only permitted for informational and non-commercial or personal use only.
